并行计算时节点分配核数有最优方式吗?
-
-
@cccrrryyy 在 并行计算时节点分配核数有最优方式吗? 中说:
后一种比前一种总会慢一些
如果有一些实测数据就好了,比如用这个算例 https://www.cfd-china.com/topic/3988/200万网格并行算力测试-openfoam版本
慢多少?如果慢个10%以内,没啥关系,如果慢很多,我也想测一下研究研究

-
“节点上任务均衡”意思应该是分配给计算域每个分区的计算量大体差不多对吧?
是呀,就是这个。就是scotch干的活。如果用GPU的话,硬件相关性比较大,可能得手动分了。
我一开始的猜想是,5:5下两台计算机每一步在互相通信5块的数据量;但如果是1:9,A计算机(1)每一步向B计算机(9)发送1块的数据量,但B计算机每一步都向A计算机发送9块的数据量,最终的通信时间就是9块的数据量。不知道这个和你说的“数据堵车”是不是一个概念?
通信确实耗时。但是等待更耗时。比如,分配到1份任务的计算机 A ,1秒就算完了,分配到9份任务的计算机 B 需要9秒才能算完。那 A 就得等8秒。而且不能干其他的事,因为大部分情况下,并行通信是“阻塞式”的,就是,一直在等着通信对象发消息,通信不完成,其他啥都不干。
这个教程挺不全面,但大概能了解并行计算的条条框框。
-
贴一下我这边测试的结果,同一个案例计算到某个固定步数,总共48核。测试时任何机器上没有别的作业,机器之间是IB网络。
单节点:1200s
双节点:24+24,810s;47+1,1190s
三节点:16+16+16,670s;2+5+41,1060s
四节点:12+12+12+12,720s;2+3+8+35,940s总结下来,一是均匀分配核数确实比不均匀要快,这点得到了证实。
二是多节点并行比单节点在均匀分配核数的情况下居然还要快,可能是因为多节点的时候机器上没有别的作业从而用了更多的计算性能?
三是多节点并行似乎也有最优的节点数量。
第二和第三点我猜测可能跟网格量、求解器、机器的内存等等都有关系,比较复杂。想请教一下,多节点并行除了通信占用的时间外,是否还有其他比较大的影响因素呢?
-
@cccrrryyy 在 并行计算时节点分配核数有最优方式吗? 中说:
多节点并行比单节点在均匀分配核数的情况下居然还要快
目前我知道这个确实如此。所以我这面做机架服务器倾向于低核心+多节点。我这面有个学生最近也在频繁的测试。目前还没有规律性数据。估计月底可以有一些结果出来。目前尚不明确。多谢你的分享。
另外对于这一部分:
三节点:16+16+16,670s;2+5+41,1060s
四节点:12+12+12+12,720s;2+3+8+35,940s
不知道你IB网络带宽多少,估计换更高的带宽,4节点会更好些
-
@cccrrryyy
内存带宽,还有CPU 的cache 都会影响。
你这个情形,同样48个processor情况下,如果都在同一台电脑上跑,那么内存,CPU cache 都是用的这一台电脑的。如果分配到4个电脑上,那么相当于总内存和总的 CPU cache 都翻了4倍。CPU 的cache,一般来说 L1 和 L2 是跟核绑定在一起的,一个核能用的是固定的,但是 L3 cache 是所有核共享的。也就是说,假设你48核一共由48M的L3 cache,那么一台电脑运行时平均一个进程只有1M L3 cache 可用,但是如果4台电脑一起运行,每台电脑出12核,那么其实是平均每个进程有4M L3 cache可用,这是后者会比前者快的一个原因。
内存带宽也是一个可能的因素,原因是类似的。 -
单节点:1200s 双节点:24+24,810s; 三节点:16+16+16,670s; 四节点:12+12+12+12,720s;我们最近测试了一些,支持了固定核数,节点越多速度越快的想法。但是 @xpqiu 大佬说一般HPC调度资源都是占满一个节点之后再分配另外一个节点。因此我们这种打法,应该属于非常理出牌。
比如你们上面这个数据,能不能测试下这种的:?
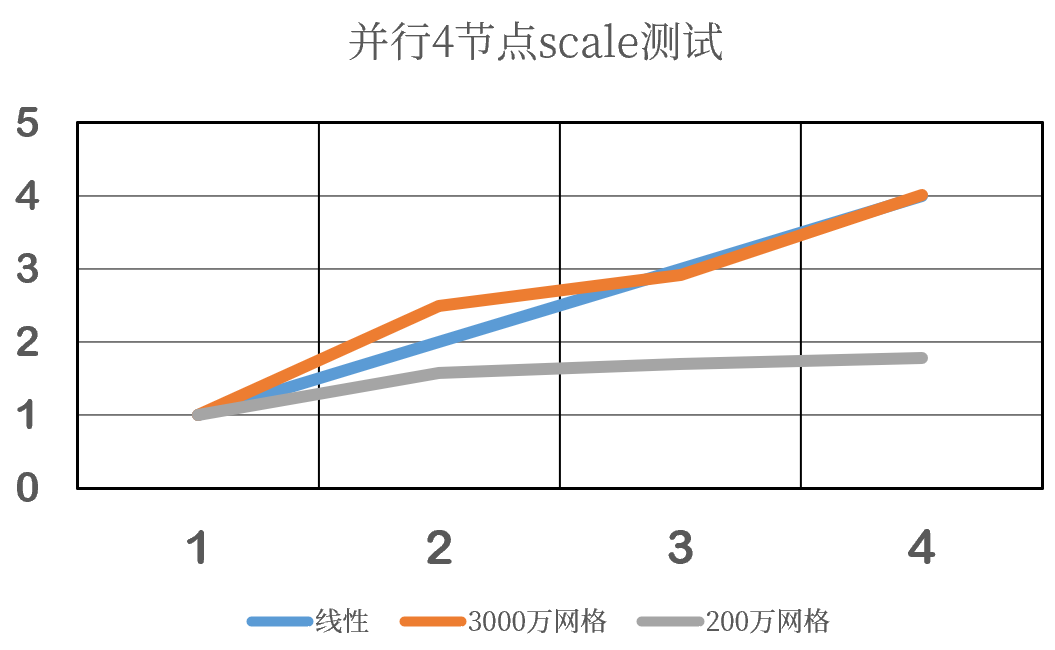
单节点:1200s 双节点:24+24 三节点:24+24+24 四节点:24+24+24+24目前我们测试到3节点之后scale的性能就不明显了。4节点反而更慢(比如4节点250核,反而不如4节点80核)。我们测试的200万、800万网格都这个样子
-
@李东岳 李老师,最近跑了下多节点并行的算例,和之前我贴出来的案例是同一个。速度如下
24:1195
24+24:809
24+24+24:500
24+24+24+24:392 (注:也跑过48+48,时间602,再次说明同样核数情况下多节点的效率很高)
24+24+24+24+24:354能看到从3节点开始效率提升就不再是线性,可能对这个网格量的算例来说3个节点已经到头,再增加节点的话性价比就开始下降,但没有出现您所说的效率反而降低的情况。
这个效率的增加其实有点超出我的预期,本来以为到了3个节点应该开始明显变慢才对。我这边单节点是64核,每个节点用24核应该远没达到机器的性能峰值,所以可能多用节点的时候计算效率提升依然很不错。
I don't want to survive, I want to thrive.

 怪不得之前在哪里看到过说L3才是影响并行计算效率的关键因素。对于并行CFD计算,可能CPU的计算快慢(主频)影响不会很大,主要还是看cache?
怪不得之前在哪里看到过说L3才是影响并行计算效率的关键因素。对于并行CFD计算,可能CPU的计算快慢(主频)影响不会很大,主要还是看cache?