请教:第三代涡识别方法Liutex的代码在linux中运行的问题
-
在浪潮上将liutex程序编译成了一个独立的程序,然后发现算的很慢,256³的网格算了半个月都没有算出一个时间步文件!
请问哪位大佬能帮我指出问题或者有什么可以并行的方法?这是代码的下载地址:http://www.jhydrodynamics.com/en/download-of-liutex-code/
-
真耐心啊,半个月了还能等

万一程序卡死了呢?或者进死循环了。
如果需要的时间步文件很大,也可以用小时间步写出来,后面删着很快的。出时间步好歹说明正常运行了。这一个时间步都没有,就不是是跑的慢还是没跑了。
如果时间步是这样的
0.01 0.011 0.012 0.013 ……或者这样的
0.010 0.011 0.012 0.013 ……那就这样
mkdir result mv 0.0? result或者这样
mkdir result mv 0.0?0 result通配符
?只匹配一个未知字符,不像*那样。很适合用来给文件分类。
然后把 result 带走,剩下的删了。写的密集断点续算也方便。滚来滚去……~(~o ̄▽ ̄)~o 滚来滚去都不能让大家看出来我不是老师么 O_o
异步沟通方式(《posting style》from wiki)(下载后打开):
https://www.jianguoyun.com/p/Dc52X2sQsLv2BRiqnKYD
提问的智慧(github在gitee的镜像):
https://gitee.com/bestucan/How-To-Ask-Questions-The-Smart-Way -
-
-
-
I am a CFD machine with no emotions.
-
I am a CFD machine with no emotions.
-
@五好青年 http://www.jhydrodynamics.com/en/download-of-liutex-code/
是这个代码么?我对liutex的计算方法不熟悉。但肯定是代码里面什么地方某个算法卡住了。
-
这种期刊的代码可以直接找通讯作者交流类似的技术问题。
-
https://www.cfd-china.com/topic/3499 在这里面有一个
获取某个函数的计算时间,你可以放在代码里面看看哪里的计算时间比较长,卡在哪里了。
-
-
I am a CFD machine with no emotions.
-
-
@李东岳
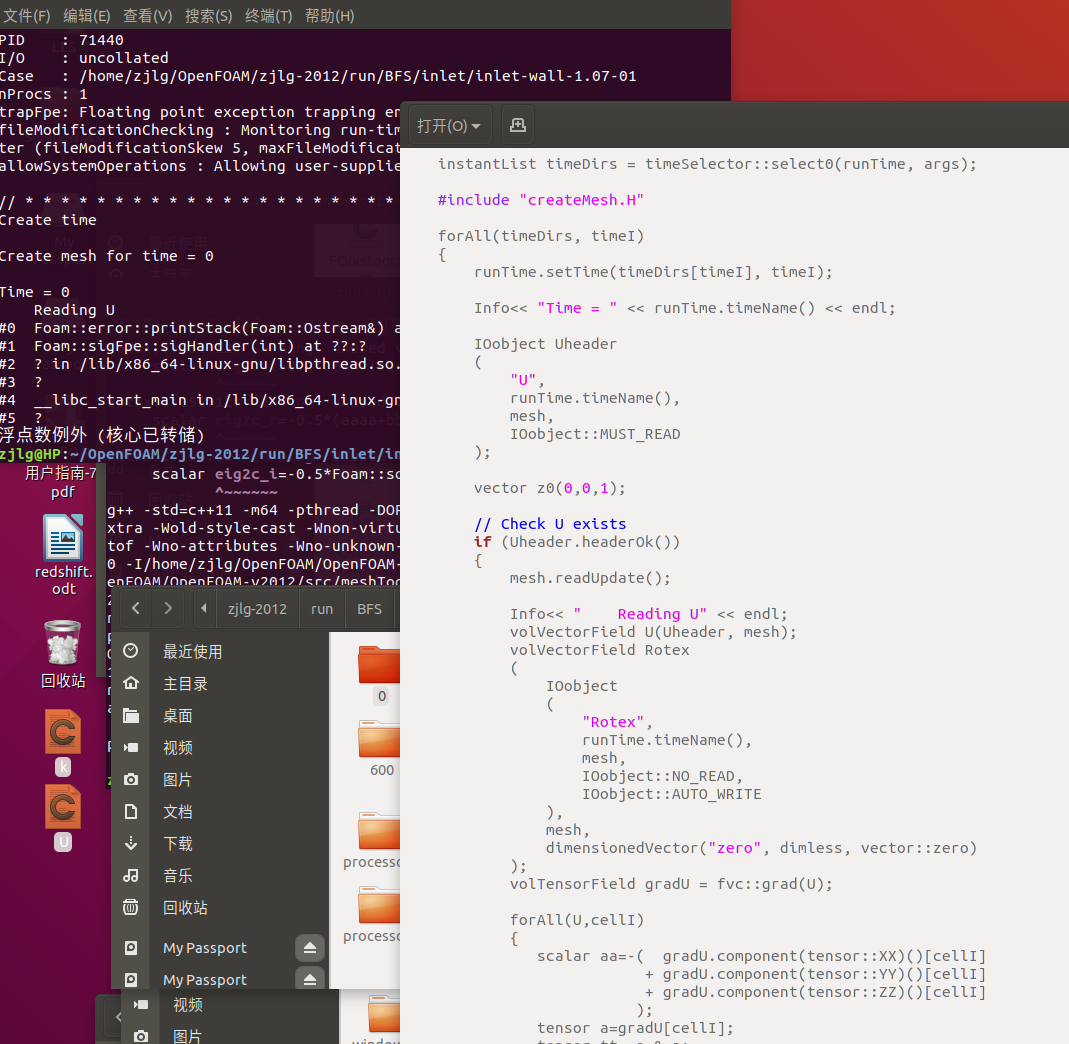
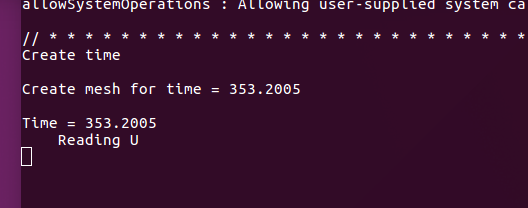
目前我将cavity算例改成三维,三个方向网格相同,试算了后进行Liutex后处理。记录如下:
30^3网格 单核,Liutex处理时间:4s
35^3网格 单核,Liutex处理时间:14s
40^3网格 单核,Liutex处理时间:60s
45^3网格 单核,单核,Liutex处理时间:131s
50^3网格 Liutex处理时间:327s
55^3网格 单核,浮点溢出
58^3网格 单核,浮点溢出
60^3网格 单核,浮点溢出
70^3网格 单核,浮点溢出
80^3网格 4核并行后处理,报错300万网格以前的算例,扩大机器内存,单核处理3天了,还没出结果
I am a CFD machine with no emotions.
-
#include <chrono> auto start = std::chrono::steady_clock::now(); // Functions here auto end = std::chrono::steady_clock::now(); auto diff = end - start; Info<< "Calculation using " << std::chrono::duration <double, std::milli> (diff).count() << " ms" << endl;你可以用上段代码测试哪个函数运行时间比较长
-
-
I am a CFD machine with no emotions.