@coolhhh 不是在个人账户下写的,我自己的账户没动过,也能在本地跑。
C
CFDngu
@CFDngu
帖子
-
求指点:集群节点上提交作业不能跑 -
求指点:集群节点上提交作业不能跑@coolhhh 谢谢您,我在网上也搜过,但是因为我没有root权限(用别人的东西)所以没办法尝试,心累。
-
求指点:集群节点上提交作业不能跑@李东岳 好的,非常感谢!
-
求指点:集群节点上提交作业不能跑@李东岳 李老师,谢谢!
之前一直没问题的,可能是最近不知道谁把集群的GCC给升级了,然后链接没做好。
对了,这个是不是需要root权限来修改?我只有本地的权限。 -
求指点:集群节点上提交作业不能跑错误如下:
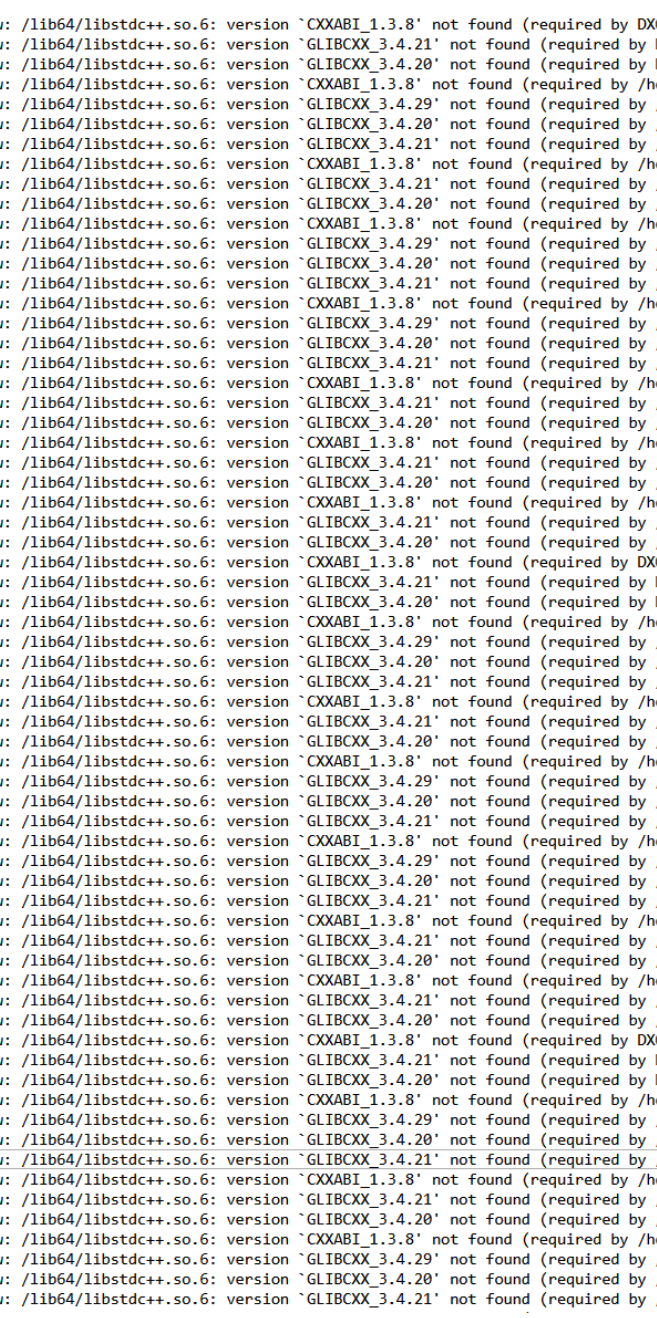
程序编译的时候没有问题,这些库我查了一下也都在的。
现在的情况是:算例在本地能跑,但是提交到节点上就出错,求各位老师指点,谢谢!
-
求助,在使用interdymfoam得到结果以后如何计算得到船舶的纵倾与横摇呢@bestucan
pi是角动量,除以转动惯量就是角速度,再乘以时间步长就是角度变化量,用来构建旋转矩阵。最近,我又看了看相关资料,发现两处比较有意思的地方:
1、6DoF定义的orientation叫做“rotation tensor”,我查过一些资料,好像tensor的旋转和vector的旋转不太一样;
2、这个旋转矩阵应该是按照左手定则来定义的,旋转向量时,pi & R 实际上执行的是R.T()*pi,左乘转置。上面两处是我个人的理解,不保证对。希望有大神能搞清楚这一块,指导一下,谢谢!(PS:虽然搞不清楚此处旋转为什么这样定义,但不能否认的是6DOF的计算准确性是可以的)
-
求助,在使用interdymfoam得到结果以后如何计算得到船舶的纵倾与横摇呢@bestucan 大佬,我借楼问一下,6DOF中的旋转为什么是这样定义的啊?没太看懂
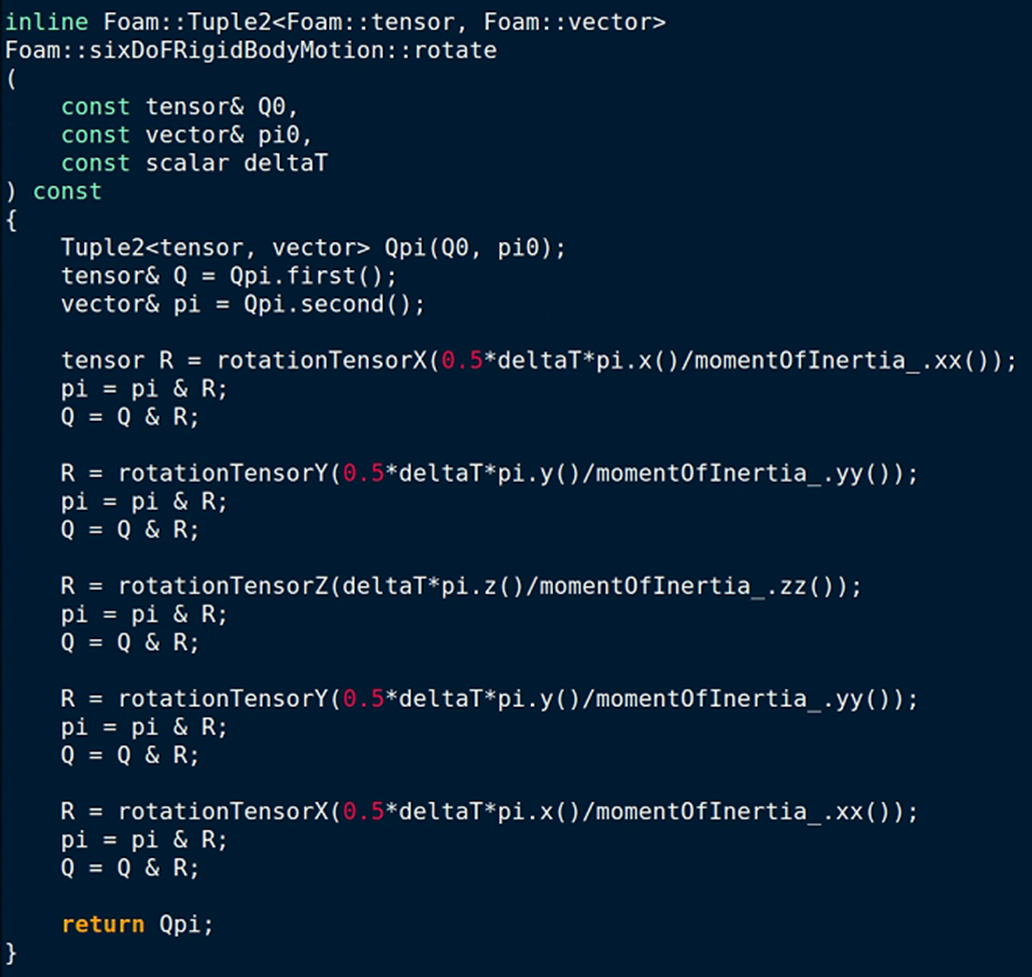
(1)这个旋转看着不像常用的右手定则,像是左手定则?
(2)为什么要按照 0.5Rx-0.5Ry-Rz-0.5Ry-0.5Rx 这种顺序旋转?求大佬解惑,谢谢!
-
求助,在使用interdymfoam得到结果以后如何计算得到船舶的纵倾与横摇呢@liujiayi 在 求助,在使用interdymfoam得到结果以后如何计算得到船舶的纵倾与横摇呢 中说:
@bestucan 在 求助,在使用interdymfoam得到结果以后如何计算得到船舶的纵倾与横摇呢 中说:
你这个句子都不是很通顺啊。。。
orientation大概就是船体的朝向了。想要算纵倾和横摇得确定两个时间点吧。
两个时间点,就有两个orientation。然后就是三维空间中两条线的夹角计算。我的意思就是在得到了orientation的九个张量以后,如何计算出来船舶的纵倾和横倾,
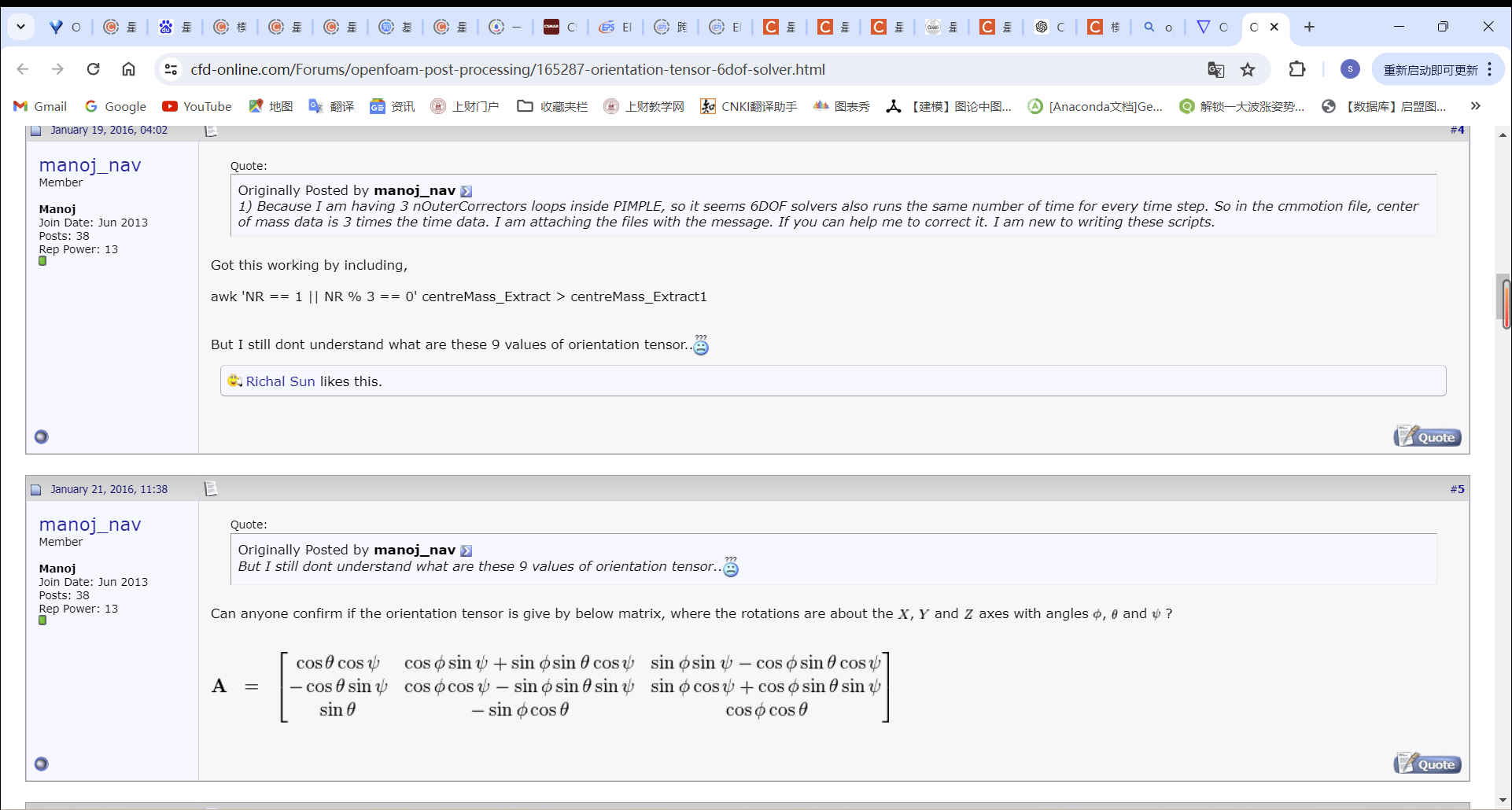 ,我在国外cfd网站上看到了有人用这种方式求出倾角,这么算对吗?求大佬指点。
,我在国外cfd网站上看到了有人用这种方式求出倾角,这么算对吗?求大佬指点。用四元数转化,quaternion(Q()).eulerAngles(quaternion:XYZ),大概这样
-
各位老师,请问我是算出棋盘型压强场了吗?@李东岳 在 各位老师,请问我是算出棋盘型压强场了吗? 中说:
知识盲区了老铁。运动大体上没问题就问题不大。不过看起来有一些小bug没处理好,也不能说肯定是压力期盼分布
运动大体上差不多,但是肯定不完全对
-
各位老师,请问我是算出棋盘型压强场了吗?各位老师好,我近期在尝试将Ghost fluid method和Overset grid结合起来,模拟浮式结构物的运动。目前的状态是,算例可以算,浮式结构物的运动大体上没问题,但是细节不对。下图是我模拟的结果,请问这个是棋盘型压强场吗?或者有什么相关文献推荐吗?非常感谢!
(GFM的求解器我已经做好了,验证没有问题,我感觉将其与Overset grid结合应该没有什么特别需要注意的地方吧)
-
200万网格并行算力测试(OpenFOAM版本)@heike256 5万
-
200万网格并行算力测试(OpenFOAM版本)@李东岳 之前慢的原因是没有插满内存,插满后试了一下,确实是80核左右最快。
结果如下:
128 42.75
80 37.13
64 43.1
32 71.04
16 93.86
8 118.65
4 222.97
2 385.11
1 799.57 -
200万网格并行算力测试(OpenFOAM版本)@heike256 不是二手,发现原因了,内存槽没插满。。
-
200万网格并行算力测试(OpenFOAM版本)CPU型号:AMD EPYC 7763 64-Core (双路)
系统:ubuntu18.04
内存:256G ddr4
OpenFOAM版本:OpenFOAM v2006
128 125.5
64 105.71
32 109.28
16 124.35
8 171.75
4 276.83
2 517.43
1 887.79超线程已关,结果不怎么样,难不成我这个是假7763?请问如何优化?(刚组的机器,没多长时间)
-
VOF方法中如何准确计算自由表面曲率?@李东岳 在 VOF方法中如何准确计算自由表面曲率? 中说:
这个方法在函数calculateK()里面,可直接调用。计算结果在3232网格上能得到光滑的结果,但不对。在6464网格上出现了数值振荡。
VOF结果在网格比较细的时候结果不对?这个结论很有挑战性
李老师,我用interIsoFoam算了一下,还是不对。在32$\times$32的网格上可以得到光滑的结果,但是和解析解不一样;在64$\times$64的网格上结果出现了振荡。interfoam也跑了一下,结果和interisofoam不一样,也不对。。。(这个算例的设置参照和解析解在主贴的参考文献[1]中)
算例在这里,大家有兴趣可以跑一下。要是算例设置有问题也可以指出来。另外,我是在v2006环境下跑的(这个链接可能需要注册坚果云,我没找到其他的上传方法
)
capillaryWave -
VOF方法中如何准确计算自由表面曲率?@李东岳 李老师,我在间断条件中加入了表面张力项$\sigma\kappa$,其中$\kappa$是用calculateK算的,结果确实不对。但这属于GFM方法,和CSF模型不同。明天我用interfoam算一下这个算例,看看结果如何。
-
VOF方法中如何准确计算自由表面曲率?各位大神,我在做Ghost Fluid Method时遇到一个棘手的问题:间断条件中自由表面曲率的计算。我选择的验证算例是Capillary wave[1]。
目前尝试了几种方法:
(1) interfoam中使用的是CSF模型,计算曲率采用如下公式:
$\vec{n} = \nabla \alpha / | \nabla \alpha| $ (1)
$\kappa = - \nabla\cdot\vec{n}$ (2)
这个方法在函数calculateK()里面,可直接调用。计算结果在32$\times$32网格上能得到光滑的结果,但不对。在64$\times$64网格上出现了数值振荡。(2) 尝试的另一种方法是采用isoAdvector,因为这个方法中自由表面法向量$\vec{n}$是根据subcell system计算的,理论上应该更准。最后曲率的计算公式还是上面的公式(2),但是结果也不对,还是会出现振荡,并且难以做到收敛。
(3) 另外,我注意到有文章讨论VOF方法中的自由表面曲率计算问题[2]。我尝试了基于RDF的方法进行计算(isoAdvector中可采用RDF重构自由表面并计算自由表面法向量[3]),但结果也不理想。
我查了相关文献,发现将表面张力加入间断条件的程序都是采用levelset法捕捉自由表面(例如参考文献[1]),其自由表面曲率可由levetset函数直接计算。但在基于VOF方法中的模型中,很少见到间断条件中包含表面张力和粘性项,都是只有一个压力的间断条件。
因此我想请教一下各位大神,有没有什么在VOF方面中准确计算自由表面曲率的好方法?或者成功的经验?非常感谢!
[1] Haghshenas M, Wilson J A, Kumar R. Algebraic coupled level set-volume of fluid method for surface tension dominant two-phase flows[J]. International Journal of Multiphase Flow, 2017, 90:13-28.
[2] Cummins S J, Francois M M, Kothe D B. Estimating curvature from volume fractions[J]. Computers & Structures, 2005, 83(6/7):425-434.
[3] Hs A, Jr B. Accurate and efficient surface reconstruction from volume fraction data on general meshes[J]. Journal of Computational Physics, 2019, 383:1-23. -
请问有并行debug的工具吗?@cp_zhao 这个我记得收费吧?不过也谢谢了~
-
请问有并行debug的工具吗?一直用gdb调试程序,但却不会并行调试。最近写的代码单核运行没问题了,但并行运行有问题,应该是不同processor交界面处出现问题。之前对并行这方面涉及不多,对并行编程思想认识不直观,故想尝试并行调试。
我在openWiki上看到一个mpirunDebug文件(文件如下),但是不会用。求大佬指点一二,或者有什么好用的并行debug工具推荐一下?

#!/bin/sh # # Driver script to run mpi jobs with the processes in separate # windows or to separate log files. # Requires bash on all processors. PROGNAME=`basename $0` PROGDIR=`dirname $0` if [ `uname -s` = 'Linux' ]; then ECHO='echo -e' else ECHO='echo' fi printUsage() { echo "" echo "Usage: $PROGNAME -np <dd> <executable> <args>" echo "" echo "This will run like mpirun but with each process in an xterm" } nProcs='' exec='' args='' while [ "$1" != "" ]; do echo "$1" case $1 in -np) nProcs=$2;shift ;; *) if [ ! "$exec" ]; then exec=$1 elif [ ! "$args" ]; then args="\"$1\"" else args="$args \"$1\"" fi ;; esac shift done echo "nProcs=$nProcs" echo "exec=$exec" echo "args=$args" if [ ! "$nProcs" ]; then printUsage exit 1 fi if [ ! "$args" ]; then printUsage exit 1 fi if [ ! "$exec" ]; then printUsage exit 1 fi exec=`which $exec` if [ ! -x "$exec" ]; then echo "Cannot find executable $exec or is not executable" printUsage exit 1 fi echo "run $args" > $HOME/gdbCommands echo "where" >> $HOME/gdbCommands echo "Constructed gdb initialization file $HOME/gdbCommands" $ECHO "Choose running method: 1)gdb+xterm 2)gdb 3)log 4)xterm+valgrind 5)nemiver: \c" read method if [ "$method" -ne 1 -a "$method" -ne 2 -a "$method" -ne 3 -a "$method" -ne 4 -a "$method" -ne 5 ]; then printUsage exit 1 fi $ECHO "Run all processes local or distributed? 1)local 2)remote: \c" read spawn if [ "$spawn" -ne 1 -a "$spawn" -ne 2 ]; then printUsage exit 1 fi # check ~/.$WM_PROJECT/$WM_PROJECT_VERSION/ # check ~/.$WM_PROJECT/ # check <installedProject>/etc/ if [ "$WM_PROJECT" ]; then for i in \ $HOME/.WM_PROJECT/$WM_PROJECT_VERSION \ $HOME/.WM_PROJECT \ $WM_PROJECT_DIR/etc \ ; do if [ -f "$i/bashrc" ]; then sourceFoam="$i/bashrc" break fi done fi # Construct test string for remote execution. # Source OpenFOAM settings if OpenFOAM environment not set. # attempt to preserve the installation directory 'FOAM_INST_DIR' if [ "$FOAM_INST_DIR" ]; then sourceFoam='[ "$WM_PROJECT" ] || '"FOAM_INST_DIR=$FOAM_INST_DIR . $sourceFoam" else sourceFoam='[ "$WM_PROJECT" ] || '". $sourceFoam" fi echo "**sourceFoam:$sourceFoam" rm -f $HOME/mpirun.schema touch $HOME/mpirun.schema proc=0 xpos=0 ypos=0 for ((proc=0; proc<$nProcs; proc++)) do procCmdFile="$HOME/processor${proc}.sh" procLog="processor${proc}.log" geom="-geometry 120x20+$xpos+$ypos" node="" if [ .$WM_MPLIB = .OPENMPI ]; then node="-np 1 " elif [ .$WM_MPLIB = .LAM ]; then if [ "$spawn" -eq 2 ]; then node="c${proc} " fi fi echo "#!/bin/sh" > $procCmdFile if [ "$method" -eq 1 ]; then echo "$sourceFoam; cd $PWD; gdb -command $HOME/gdbCommands $exec 2>&1 | tee $procLog; read dummy" >> $procCmdFile #echo "$sourceFoam; cd $PWD; $exec $args; read dummy" >> $procCmdFile echo "${node}xterm -font fixed -title 'processor'$proc $geom -e $procCmdFile" >> $HOME/mpirun.schema elif [ "$method" -eq 2 ]; then echo "$sourceFoam; cd $PWD; gdb -command $HOME/gdbCommands >& $procLog" >> $procCmdFile echo "${node}$procCmdFile" >> $HOME/mpirun.schema elif [ "$method" -eq 3 ]; then echo "$sourceFoam; cd $PWD; $exec $args >& $procLog" >> $procCmdFile echo "${node}$procCmdFile" >> $HOME/mpirun.schema elif [ "$method" -eq 4 ]; then echo "$sourceFoam; cd $PWD; valgrind $exec $args; read dummy" >> $procCmdFile echo "${node}xterm -font fixed -title 'processor'$proc $geom -e $procCmdFile" >> $HOME/mpirun.schema elif [ "$method" -eq 5 ]; then ## maybe could use nemiver sessions for reloading breakpoints --session=<N> or --last # echo "$sourceFoam; cd $PWD; nemiver --last $exec $args; read dummy" >> $procCmdFile echo "$sourceFoam; cd $PWD; nemiver $exec $args; read dummy" >> $procCmdFile # echo "$sourceFoam; cd $PWD; ddd --args $exec $args; read dummy" >> $procCmdFile echo "${node} $procCmdFile" >> $HOME/mpirun.schema fi chmod +x $procCmdFile let column=proc%6 if [ $proc -ne 0 -a $column -eq 0 ]; then ((xpos+=600)) ((ypos=0)) else ((ypos+=200)) fi done for ((proc=0; proc<$nProcs; proc++)) do procLog="processor${proc}.log" echo " tail -f $procLog" done $ECHO "Constructed $HOME/mpirun.schema file. Press return to execute.\c" read dummy if [ .$WM_MPLIB = .OPENMPI ]; then mpirun -app $HOME/mpirun.schema </dev/null elif [ .$WM_MPLIB = .LAM ]; then mpirun $HOME/mpirun.schema </dev/null fi -
fvc::intergrate(fvc::grad(phi))*nf不等于snGrad(phi)?@李东岳 好的,谢谢李老师。我发现面上梯度可通过fvc::reconstruct这个函数重构出的体心梯度,我还是得研究一下这个函数。比如刚刚的重力源项,定义在面上的话,我还没掌握怎么把它放回控制方程里面
