OpenFOAM libtorch tutorial step by step
-
@李东岳 李老师您好,我在看您发的那个顶盖驱动流的代码的时候有个问题,我的电脑安装了openfoam10和11,同样的文件内容为什么在of10下我可以成功编译,但在of11下不可以呢。在11下,一开始提示找不到libtriSurface.so和libsurfMesh.so,然后我在bashrc中添加了,export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/john/OpenFOAM/OpenFOAM-11/platforms/linux64GccDPInt32Opt/lib,随后再次运行出现了这样的问题。

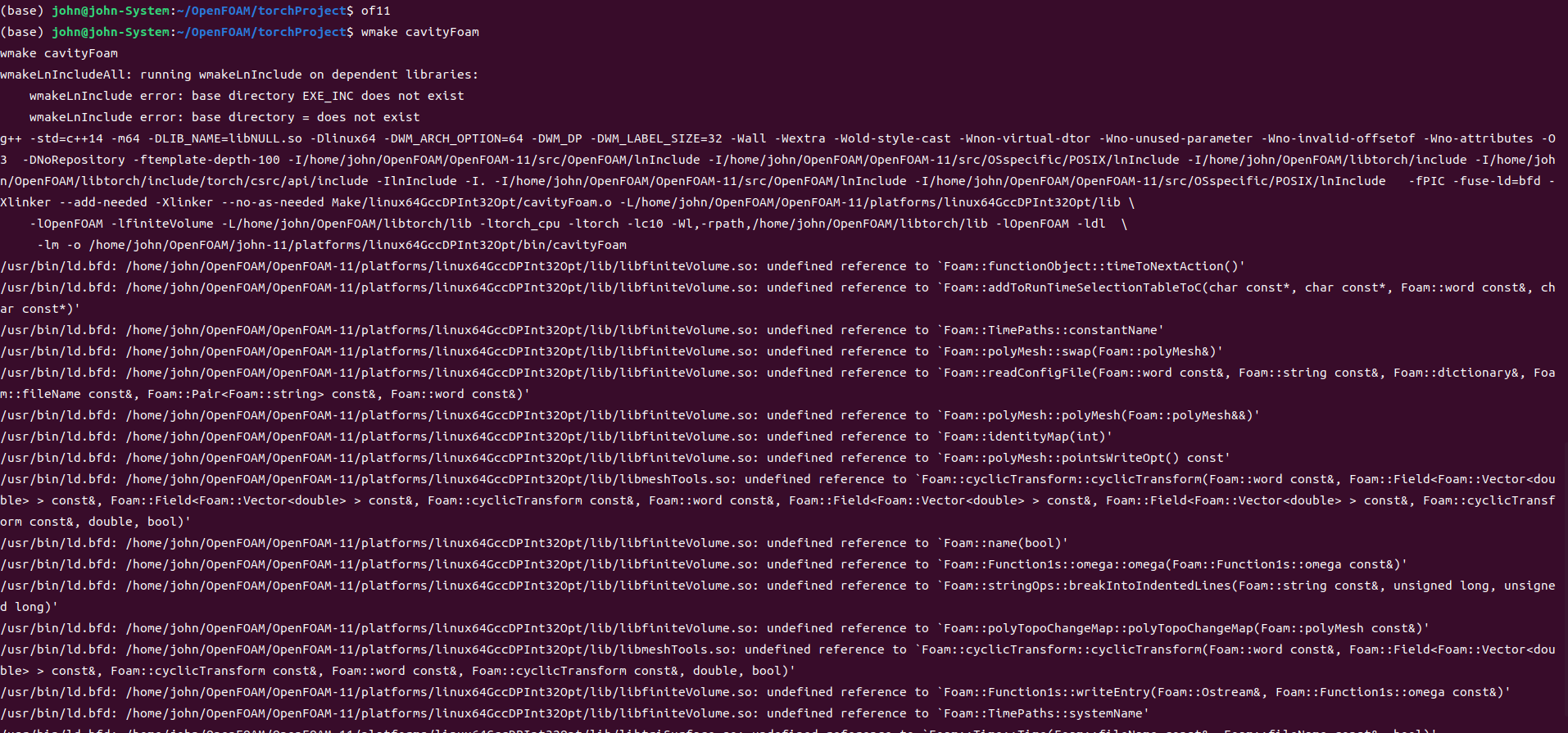
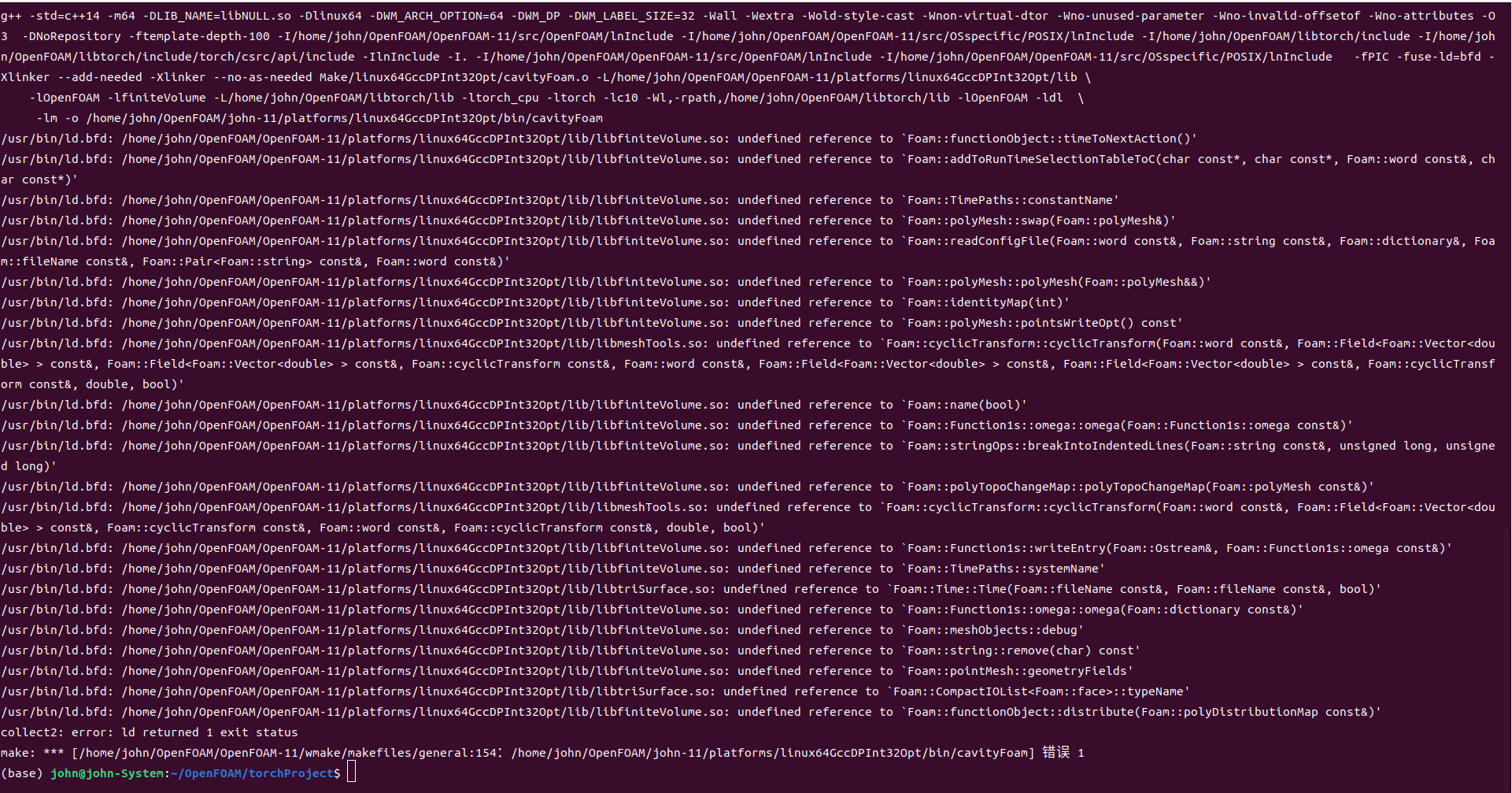
-
-
@李东岳 李老师您好,我在复现您这个例子的时候有一些细节有些糊涂?想请问您具体是怎么做的呢,能分享一下您的算例吗
@李东岳 在 OpenFOAM libtorch tutorial step by step 中说:
代码越来越复杂。这是执行一系列的卷积、池化操作等输出的8个通道的流场结果:
http://dyfluid.com/cnn.html#id6
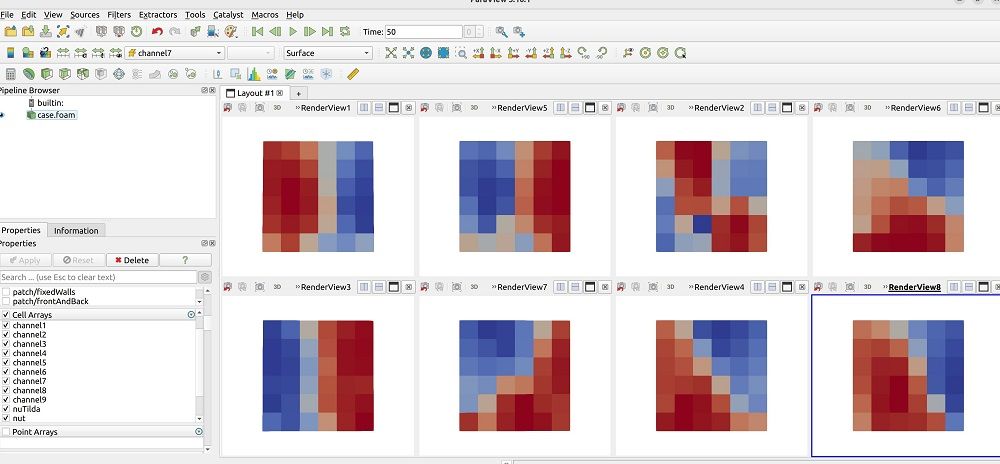
下图是自编码器进行重组的流场:

-
CNN处理的时候,你需要生成不同的OpenFOAM网格,http://dyfluid.com/cnn.html#id6 我在这里面做了4次池化,那你就需要4套openfoam网格
我有这个算例,但是代码都是课堂现写,之前都是计划LCO课堂给大家讲的算例,写完了代码之后用我准备的算例去验证,后来大家一听一个不吱声,太难不讲了。目前我对CNN这方面也没有之前那么高涨,还没有重写代码的计划。
-
老哥,我把东岳老师那个1D槽道流的代码用AI改成了CUDA版本。然后在https://download.pytorch.org/libtorch/cu117 (我的cuda版本是11.7)下载的gpu版本的libtorch。现在发现已经可以用gpu训练了,但是训练速度还不如cpu,慢不少。 准备后续再捣鼓一下。 我机器配置 GPU: nvidia T400 4G, CPU:I7-12700,供参考
#include <torch/torch.h> #include <torch/cuda.h> // 添加CUDA支持 using namespace std; class NN : public torch::nn::Module { torch::nn::Sequential net_; public: NN() { net_ = register_module("net", torch::nn::Sequential( torch::nn::Linear(1,8), torch::nn::Tanh(), torch::nn::Linear(8,1) )); } torch::Tensor forward(torch::Tensor x) { return net_->forward(x); } }; int main() { // 设备检测与设置 torch::Device device = torch::kCPU; if (torch::cuda::is_available()) { std::cout << "CUDA可用,使用GPU加速训练" << std::endl; device = torch::kCUDA; } int iter = 1; int IterationNum = 1000000; double learning_rate = 0.001; double dy = 0.00125; int cellN = static_cast<int>(0.05/dy); // 模型迁移至GPU auto model = std::make_shared<NN>(); model->to(device); // 优化器 auto opti = std::make_shared<torch::optim::AdamW>( model->parameters(), torch::optim::AdamWOptions(learning_rate) ); // 数据迁移至GPU (关键步骤!) auto init = torch::full({}, 1.0).to(device); auto mesh = torch::arange(-0.05, 0, dy, torch::requires_grad()) .unsqueeze(1).to(device); auto dpdxByNu = torch::ones({cellN, 1}, torch::kFloat).to(device); auto nut = torch::zeros({cellN}).to(device); for (int i = 0; i < IterationNum; i++) { opti->zero_grad(); auto upred = model->forward(mesh); // 梯度计算(确保权重张量在GPU) auto dudy = torch::autograd::grad( {upred}, {mesh}, {torch::ones_like(upred).to(device)}, true, true )[0]; auto dudyy = torch::autograd::grad( {dudy}, {mesh}, {torch::ones_like(upred).to(device)}, true, true )[0]; auto dudyTop = dudy[cellN - 1][0]; auto meanU = torch::mean(upred); auto ubottom = torch::full_like(upred[0], 0.0375).to(device); // 边界条件迁移 auto dpdxByNu = torch::full({cellN}, 1.2e-05/1e-08).to(device); // 损失计算 auto loss_bottom = torch::mse_loss(upred[0], ubottom); auto loss_top = torch::mse_loss(dudyTop, torch::zeros_like(dudyTop)); auto loss_bd = loss_bottom + 1000*loss_top; auto loss_ini = 1000*torch::mse_loss(meanU, init); auto loss_pde = torch::mse_loss(-dudyy.reshape({cellN}), dpdxByNu); auto loss = loss_pde + loss_bd + loss_ini; // 反向传播 loss.backward(); opti->step(); // 输出需同步到CPU if (iter % 500 == 0) { double loss_value = loss.item<double>(); cout << iter << " loss = " << loss_value << endl; } iter++; } torch::save(model, "model.pth"); std::cout << "训练完成!" << std::endl; return 0; }