openfoam中cyclic周期性边界的问题
-
-
我也曾遇到非常类似的问题,我就有一个液滴在一段小管子(两边cyclic)中移动,速度不够大的时候,就发现液滴移动到一头出不去,需要等很久才能出去,明显是有问题;然而速度达到一定程度,看起来就能自由出去然后从cyclic的另一端进来,不过我也不知道为什么。。。
-
不知道把计算域扩大效果会怎么样?
是要观察油滴气泡的上升速度和 其它参量的关系? 一定要用cyclic 边界吗?或者说为什么要用周期边界条件?
-
@xiaofenger 这个已经困惑我很长时间了,可是我的油滴还有气泡都是自然上升启动的,也就是说到达边界时速度很小,如果可以的话,可以私下交流一下吗,谢谢!
-
@random_ran 是的,重在研究相关关系,而且我是油滴气泡群,所以得用周期性边界!你说的扩大计算域,是为了让气泡到达边界时速度更大吗
-
Yours in CFD,
Ran
-
@random_ran 不管怎么样,都要谢谢你的解答!我先试一试,等有结果了再与你交流~
-
@xiaofenger 你好,我也是这方面的新手,我就是想问问你的算例最后怎么跳出时间步长特别小的情况,我今天又重新跑了算例,发现还是有问题!qq:768620698,谢谢!
-
@xiaofenger 你好,我还想问一下请问一下你用的是cyclic还是cyclicAMI边界,另外你用的是VOF模型吗?谢谢~
-
-
长风破浪会有时,直挂云帆济沧海
-
-
长风破浪会有时,直挂云帆济沧海
-
cyclic BC是个大坑,因为OF的理论和编程经常不自洽。感觉网上从来没说清楚过。刚才我才搞明白。
-
首先,face addressing的owner, neighbour和ldu addressing的lower, upper并不天然等价。face addressing描述的的网格的几何拓扑关系。而ldu addressing需要描述的的是数值拓扑关系,如果没有耦合边界,二者是等价的,但是如果有耦合边界,就有了face addressing描述不了的off-diagonal term。这就有两种处理方式:
-
在OF+1706中,有两种lduAddressing,包括
fvMeshLduAddressing和fvMeshPrimitiveLduAddressing。- 实际上
fvMeshLduAddressing是将face addressing和ldu addressing等价了,内部面的owner就是lower,neighbour就是upper。这也是最最常用的类型,可以称之为普通ldu。 - 而
fvMeshPrimitiveLduAddressing(这里的Primitive的意思是not developed or derived from anything else)中的lower可以添加owner之外的相互作用关系。但是这个类位于overset目录下,可见它主要用于重叠网格的情况,可以称之为overset ldu。
- 实际上
-
而coupled BC是实现在普通ldu中。依靠两个类:
coupledFvPatch和coupledFvPatchField,其中关键是他们各自继承了lduInterface和lduInterfaceField,并实现了相关函数。所以其实interface和coupled BC是几乎同样的概念。 -
从概念上讲,对于普通LDU,在有interface的情况下虽然在lduMatrix中存了upper,diag,lower矩阵系数,但是还有额外耦合项,也就是说$A=L+D+U+C\ne L+D+U$,$C$就是额外耦合项,由于数据结构设计上的限制,不能存到普通ldu的矩阵中,需要单独处理。
-
处理方式也比较简单,$C$因为也是代表cell-cell相互作用,所以主要是非对角的,因为对角的部分完全可以包含在$D$中,而且源项部分也可以容纳在原来的源项里,可以分裂为上下两部分,$C=C_L+C_U$。在
lduMatrix.Amul()的操作中,计算$A\cdot x$的操作被分为$D\cdot x+(L+U)\cdot x +C_U\cdot x_n $:initMatrixInterfaces: $C_L\cdot x_o$,其中$x_o$是$x$中属于耦合边界的内侧单元,计算结果要送到另一侧去;- all cells:
ApsiPtr[cell] = diagPtr[cell]*psiPtr[cell];: $D\cdot x$ - all faces:
ApsiPtr[uPtr[face]] += lowerPtr[face]*psiPtr[lPtr[face]];: $L\cdot x$ - all faces:
ApsiPtr[lPtr[face]] += upperPtr[face]*psiPtr[uPtr[face]];: $U\cdot x$ updateMatrixInterfaces: $C_U\cdot x_n$,其中$x_n$只包含$x$中属于耦合边界的外侧单元;- 这种$C\cdot x$叫做
patch Contribution。 $C_L, C_U$叫interfaceUpper,interfaceLower。
-
问:为什么$C_L,C_U$要分开处理?答:因为在存在processor边界时,$x_n$并不在本地,要通过通信获取结果,或者获取系数。
-
问:$C_L$和$C_U$存在哪儿?答:
-
class fvMatrix : public refCount, public lduMatrix { //... //- Boundary scalar field containing pseudo-matrix coeffs // for internal cells FieldField<Field, Type> internalCoeffs_; //注意这里不是引用,是真货 //- Boundary scalar field containing pseudo-matrix coeffs // for boundary cells FieldField<Field, Type> boundaryCoeffs_; //都初始化为0; //... }
-
-
coupled BC, interface, constraint BC等的关系:
interface就是coupled BC,constraint BC是OF文档中的分类,其实包含了empty, wedge,symmetry等几何约束类的BC和coupled BC。coupled BC中比较重要的两类是cyclic和processor。
总的来看cyclic边界条件本身的实现应该没有问题,还挺巧妙的。
回到这个问题,我觉得可能是CFL数计算的部分可能在cyclic BC处有bug。
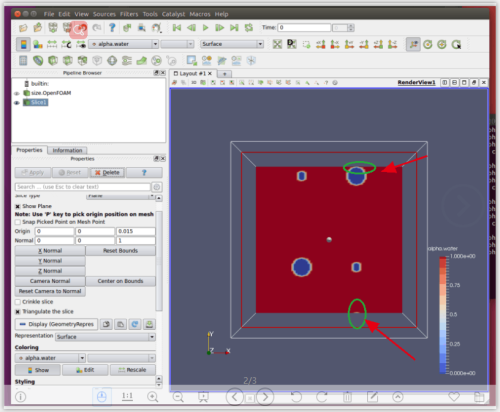
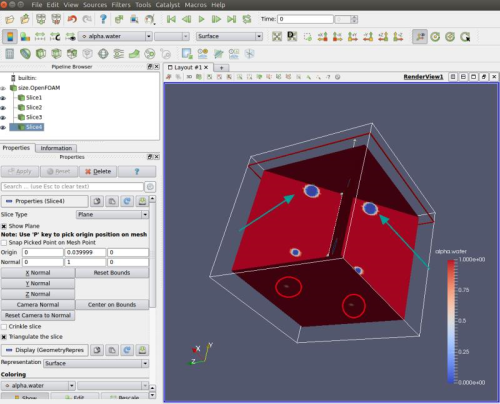
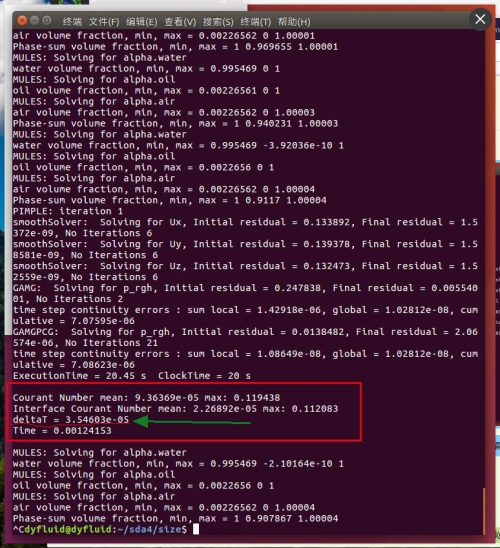
Courant数计算方式来看,普通Courant数和其他一样,额外多了一个Interface Courant数。里面多了个这玩意儿:scalarField sumPhi ( mixture.nearInterface()().primitiveField() *fvc::surfaceSum(mag(phi))().primitiveField() ); alphaCoNum = 0.5*gMax(sumPhi/mesh.V().field())*runTime.deltaTValue(); meanAlphaCoNum = 0.5*(gSum(sumPhi)/gSum(mesh.V().field()))*runTime.deltaTValue(); // mixture.nearInterface()(),定义是: Foam::tmp<Foam::volScalarField> Foam::interfaceProperties::nearInterface() const { return pos(alpha1_ - 0.01)*pos(0.99 - alpha1_); }可能是相边界速度太大了吧。估算一下有上万了,你的平均Courant这么小,最大Courant这么大。。。你又是这么均匀的网格。。
-