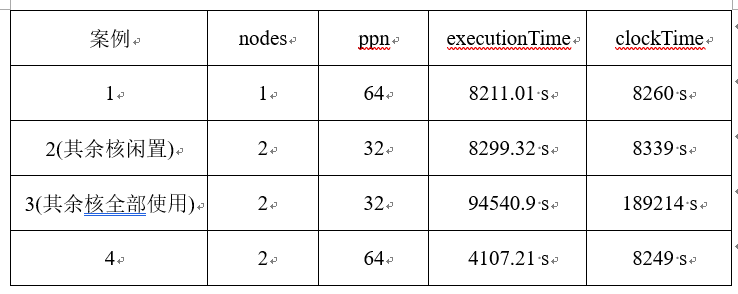
跨节点运行openfoam慢
-
滚来滚去……~(~o ̄▽ ̄)~o 滚来滚去都不能让大家看出来我不是老师么 O_o
异步沟通方式(《posting style》from wiki)(下载后打开):
https://www.jianguoyun.com/p/Dc52X2sQsLv2BRiqnKYD
提问的智慧(github在gitee的镜像):
https://gitee.com/bestucan/How-To-Ask-Questions-The-Smart-Way