AMD 新CPU好像测试结果还不错啊
-
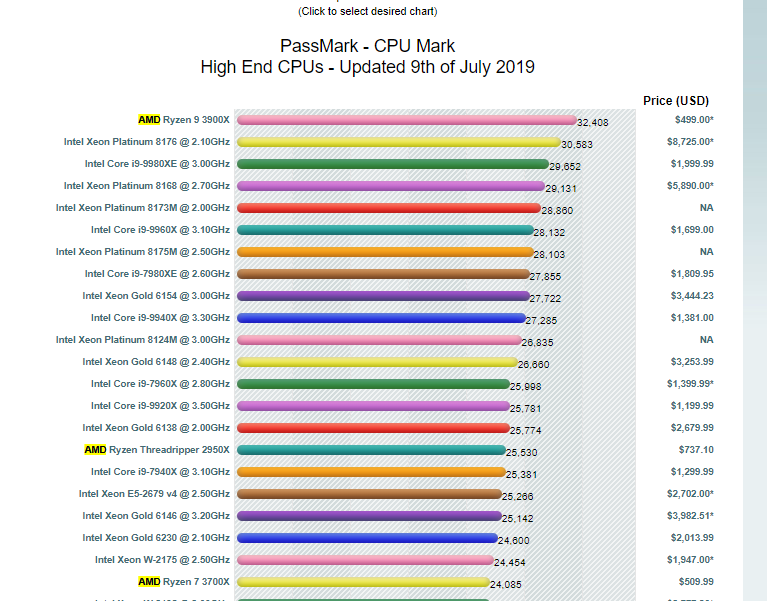
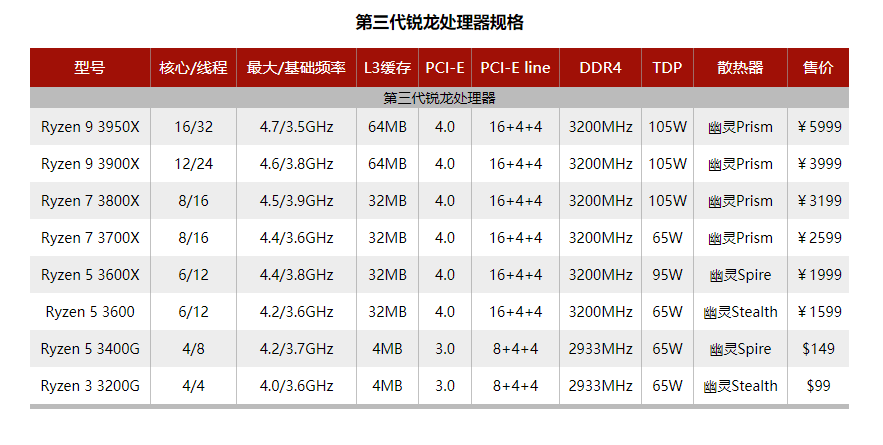
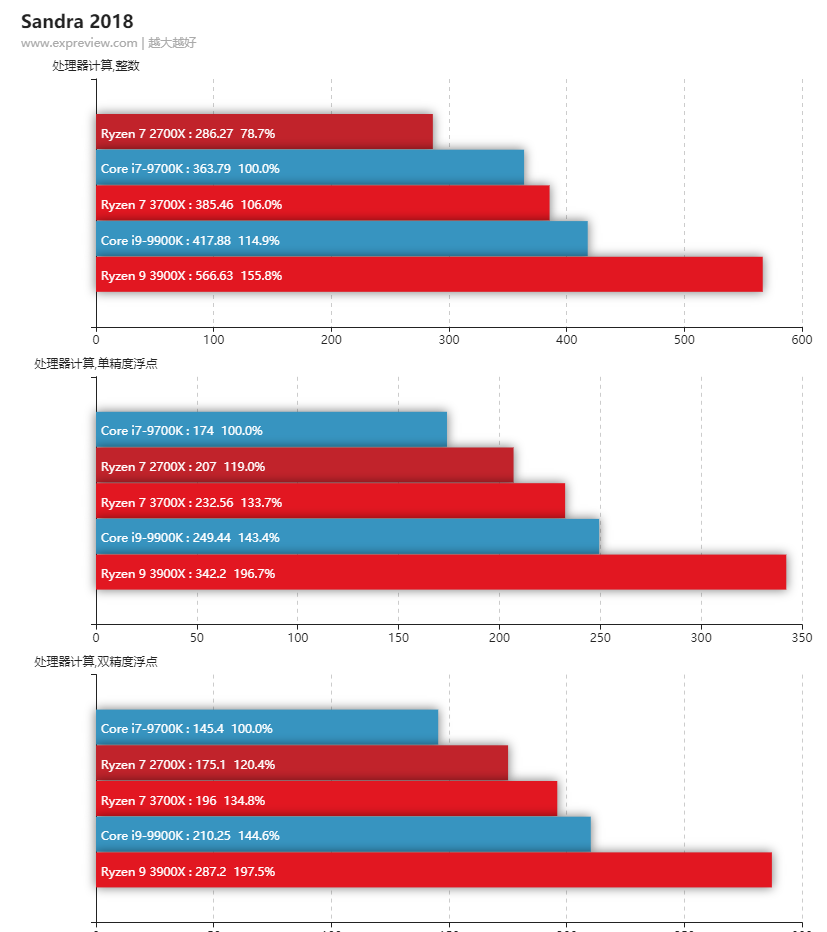
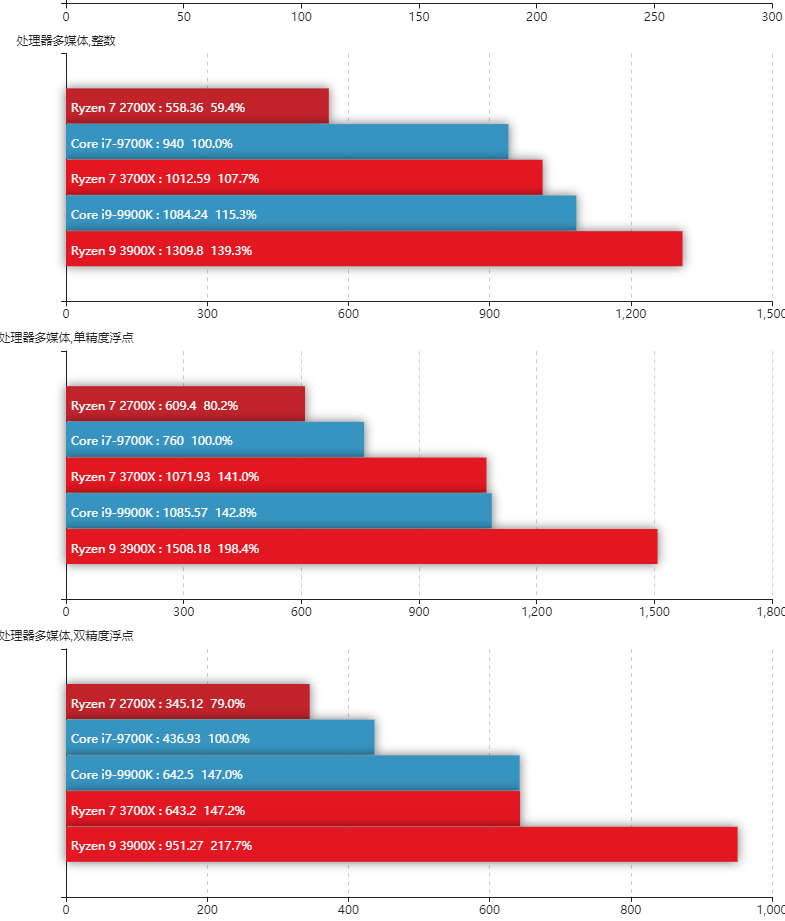
最近AMD Ryzen 3系CPU出来了,感觉测评效果还不错,CPU Benchmark网站上的结果看单CPU 3900X居然能超 铂金8176 排第一了。而且说浮点单元增加了一倍,双精度的测试数据也很好,有没有大佬测试一下CFD的!
-
世界那么大,怎能不去看看
-
@红豆沙 快上结果啊!
话说今天在cupbenchmark 上看到农企的7742跑分已经是intel家最高端的1.5倍还多了,intel要努力了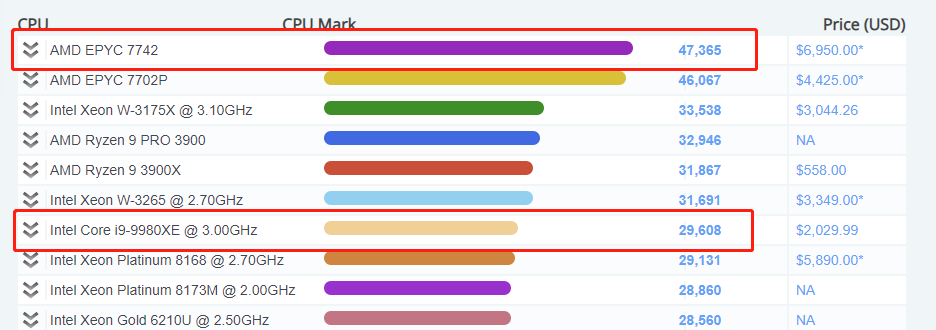
-
@hurricane007 感觉 我算 速度很YES,不过我作为单机的计算,网格数量 在百万级以下的瞬态计算,速度和 至强金银牌差不多,,最后,,还是很吃内存的多通道的,,而且 多线程感觉优势 有些,,所以 在 我认为在大型计算前,,才能发挥出,主频和架构优势 ,
-
@红豆沙 顺便说一下啊,,我的计算因为网格少,,且瞬态每个时间的迭代次数少,,所以感觉速度差不多,并行超过4核后,速度基本变化不大了,但是 个人直觉,3900X,就以主频来说,我可以调电压到1.3V超到4.2G,主频比志强的肯定要强,,我们实验室 刚刚看了是银牌4110 记错了,,哈哈,还有个2643V4,,其余的也不说了 差不多配置,,感觉让我算起来速度差不多,,AMD高主频优势体现不出来,可能和我的计算也有关,但是 多线程下,,有那么感觉 快些,,对比是
再者,人说INTEL和AMD的数学库,虽然Intel占优,但我们基本估计用不到那么多,可能这个优势也就不叫优势了,,这个要看U,估计得上 稍微大点的计算,,结果才可靠呢,,我这电脑 暂时 没装双系统,只是用的虚拟机,,可以试试 这个模拟 @东岳
再者性价比高呀,啊哈哈哈,,配下来 才刚刚1W出头的电脑,,主板还是 ROG的,,性能也是刚刚的,,你就挡不住便宜啊 全货京东,配下来 配件什么的 也很放心,,加装个显卡,,还能打打游戏 ,,,
-
世界那么大,怎能不去看看
-
世界那么大,怎能不去看看
-
世界那么大,怎能不去看看
-
@hurricane007 有具体结果了 你可以看看哈,,,,6核,12核,超线程24核,6核是59.8s和165s
世界那么大,怎能不去看看
-
-
@hurricane007 @东岳 这估计 在6核的时候,就达到了 需要的计算资源,剩下的就交给信息交换,,也就是跟内存这边有关了,,所以 你就算涨到12核,,有内存拖后腿,,你还是得用这么些时间。,,,所以数值计算 内存速度影响挺大的,,例如,,同样16G,,肯定28两个条子的,比116的条子速度快。。
估摸着也还有啥别的影响原因,,总得来讲,,
应该 这个计算6核就可以喂饱了,因为计算不光是CPU在这屋里哇啦的 一顿埋头苦干,也还得有进出交换信息啥的,,一来一去也就是,,就像你往屋里搬砖,6核一人搬4页砖,12核一人搬2页砖或者有人搬多有人搬少,但是这个门就这么大,一次最多允许你搬24页砖,,所以,你就算拉上12核也发挥不出来他的实力了。
不知道 我这样说对不对 哈哈
 有没有电脑大神来指教下
有没有电脑大神来指教下 -
农企的新HEDT 平台TR 3970X也出来了,AMD yes就对了。。。有没有大佬上这个处理器试试的。。。
https://www.expreview.com/71752.html -
