OpenFOAM并行测试
-
不同处理器的性能测试
测试方法:
-
打开simpleFoam的motorBike算例,修改decomposeParDict文件中的
method simple为method scotch;跑6核 -
./Allrun直接运行,运行后看运行时间
测试过程中执行时间和钟表时间基本没区别,因此只显示clockTime。计算机网格数量不是特别多,默认内存、固态硬盘不存在瓶颈。我用的是OpenFOAM6,simpleFoam已经很稳健了版本更新不会有太大变化
simpleFoam的运行时间对比:
计算时间 AMD EPYC 7452 88 志强金牌5120 124 志强E5 2678 v3 130 志强金牌6142 149 AMD2990w 161 AMD3900X 164 i7-9750H 229 i7-5820K 295 i7-6700 300 snappyHexMesh的运行时间对比:
6核 计算时间 AMD3900X 59.8 志强6142 68 志强金牌5120 72 i7-9750H 72.5 i7-5820K 160 买CPU关注使用核心数还是线程数?
处理器:志强5120金牌14核心*2
内存:96G
求解器:OpenFOAM-5.x
网格数量:210万六面体
模型:单相流N-S方程管道quasi-DNS模拟
悲剧,上面这个图没有贴40线程和56线程计算的图,总之就是更慢..
对本帖总结一下:
-
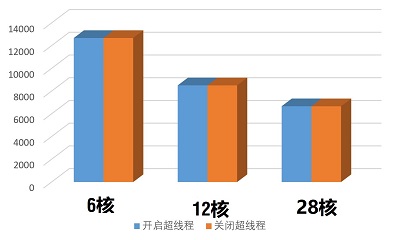
买CPU的时候计算只看核心数就好!!! 不用关心线程数。比如6核12线程,那你计算时候只能用6核!24核48线程,那就是24核!
-
AMD那面测试几个处理器跑求解器要比intel的慢,画网格要快,目前原因不详,有人知道请分享
-
谁有新的处理器能够测试的,欢迎提供数据
-
-
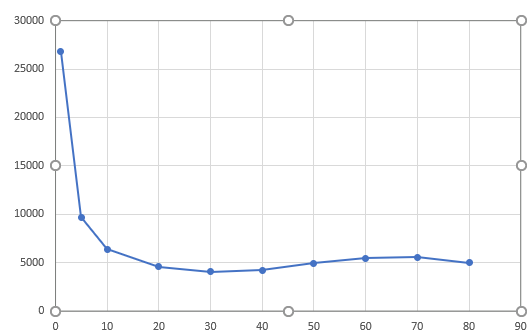
楼上的说法我可以提供一点佐证。处理器是至强E5-2679v4,40核心80线程,32G内存。网格数记不清了,大概160到180万多面体-六面体混合网格。VOF,k-omega SST, Sliding Mesh。纵轴是时间,单位是秒,横轴是线程数,图是随手画的,领会精神就好:
-
热衷于做实验搭计算环境的CFDer
-
@东岳 学校的cluster,志强 6142。用的slurm,但是我不会直接提交Allrun,所以就只测试了6核(在本地运行太多怕被网管揍)
snappyHexMesh, 67.79s
simpleFoam, 149s
不过说明上说这个机器不适合MPI运行,最开始的时候出了个warning[[51384,1],0]: A high-performance Open MPI point-to-point messaging module was unable to find any relevant network interfaces: Module: OpenFabrics (openib) Host: dragon2-ctrl0 Another transport will be used instead, although this may result in lower performance. NOTE: You can disable this warning by setting the MCA parameter btl_base_warn_component_unused to 0. -
@东岳 1812
-
@东岳 另外一个cluster上更搞笑,处理器是 志强 5118@2.3G, OF4.1,也是本地运行,均为6核,不过太慢估计是有别的原因
snappyHexMesh 96.72s
simpleFoam ExecutionTime 250.07s, ClcokTime 661s。感觉前者比较可信,因为这是个登录和编译用的节点,估计用的人比较多,后台线程比较多了。
也是有个warning-------------------------------------------------------------------------- WARNING: No preset parameters were found for the device that Open MPI detected: Local host: lm3-m001 Device name: i40iw1 Device vendor ID: 0x8086 Device vendor part ID: 14290 Default device parameters will be used, which may result in lower performance. You can edit any of the files specified by the btl_openib_device_param_files MCA parameter to set values for your device. NOTE: You can turn off this warning by setting the MCA parameter btl_openib_warn_no_device_params_found to 0. -
世界那么大,怎能不去看看
-
-
世界那么大,怎能不去看看
-
-
世界那么大,怎能不去看看
-
@东岳 我找个时间研究下怎么提交Allrun的script。。。
-
今天终于想起把鸽了这么久的事情干了一下了,今天测试的是5118 2.3G. OpenFOAM 4.1
因为是服务器,所以先运行了surfaceFeatureExtract,blockMesh, decomposePar 以后,再用slurm 分别提交snappyHexMesh 和simpleFoam,运行完snappyHexMesh 以后把Allrun里面的这两行也运行一下再提交patchSummary, potentialFoam 和simpleFoam。不过是log文件里面是分别计时的,所以应该没影响。ls -d processor* | xargs -I {} rm -rf ./{}/0 ls -d processor* | xargs -I {} cp -r 0.orig ./{}/0snappyHexMesh
6C: 99.52 s
12C: 71.93 s
24C: 59.36s
simpleFoam
6C: 237 s
12C: 158 s
24C simpleFoam 时间是86s, 基本符合预期
