你要的OpenFOAM编程杂七杂八
-
因为最近又开始重写求解器代码,代码又搞得有点多。本篇文章谈一谈OpenFOAM代码方面的杂七杂八,不谈CFD算法,只是编程,算是这些年写代码,重写代码,再重写代码,再再重写代码的总结。
OpenFOAM的入门请参考:OpenFOAM入门建议
第一句:可能有些刚入门CFD的朋友不知道我说的是什么,但你总会明白的。
开源和闭源
现在CFD软件非常多,相对于ANSYS Fluent,OpenFOAM最大的特点是开源,也就是代码是公开的。因此我们可以从代码这方面把所有的CFD软件分为:
- 闭源CFD求解器,例如
- ANSYS Fluent
- Star-CD
- 开源CFD求解器,例如
- OpenFOAM
- PyFR
比较直观的就是闭源Windows以及开源Linux,开源和闭源虽然只是代码是否公开的问题,但是导致截然不同的运营体系。
我们以ANSYS Fluent来举例,据我所知是世界上用户群最大的CFD软件,用户群远大于OpenFOAM。作为一个闭源软件,ANSYS Fluent起码要承担以下的任务:
- 所有发布版本的bug修复
- 新版本的开发
- 友好的用户接口
上面只是简单几项,当然ANSYS Fluent做的事情要比这几个多出几百倍。需要注意的是,这些都是ANSYS公司内部人员需要处理的,因此就需要雇佣大量的人员去处理,那么ANSYS就需要通过闭源Fluent去盈利来循环整个系统。
为什么OpenFOAM开源了?开源有什么好处?
Weller没有告诉我当时为什么把OpenFOAM开源化。但我猜想有以下可能:
- Weller是一个狂热的开源软件抵制者(我从他话语中判断出来的,不清楚是他后来变成这个样子还是刚出生就是开源战士 :big_mouth: )
开源CFD软件由于不从用户那收费,因此发布者并没有义务去做bug修复,因此开源软件强调的是
- 软件是大家的,bug是大家的,bug一起改,发布一起用
例如Linux,世界上大量的公司在用linux,大量的公司甚至个人发现bug之后,可以修复,经发行商采用就可以发布。目前OpenFOAM也是用的这种策略。各大公司也会赞助OpenFOAM基金会,个人也可以写求解器并且提供给OpenFOAM基金会。bug大家一起改,然后OpenFOAM基金会统一发布。
开源有什么坏处?
一旦开源,就会存在很多的衍生版本,比如你看到了各种各样的Linux发行版,例如Ubuntu,OpenSUSE,Arch等。很遗憾的是在中国,国外的开源软件有些情况下会变成自主创新。比如国外的
Android被小米摇身一变打造成自主创新内核的MIUI。国外的版权意识比较良好,并且也是百花齐放,比如各种基于OpenFOAM的CFD代码,比如做的比较大的:- ESI-OpenFOAM
- foam-extend
- SimScale
等。类似这种基于OpenFOAM的CFD代码我见过不下几十个。
想当然大家会发现OpenFOAM版本号最近更新的比较快,比如从OpenFOAM-4.1直接步进到OpenFOAM-5.0。这都是有原因的,存在商业的原因。
面向对象和面向过程
由于OpenFOAM和ANSYS Fluent最大的区别在于开源和闭源。因此大多数用户使用OpenFOAM需要调用起开源的特性,也就是需要对OpenFOAM的代码进行改动。否则用户会选择更加友好的闭源CFD软件。
下面是一个简单的C++代码:
void foo(int y) { using namespace std; cout << "y = " << y << endl; } int main() { foo(5); int x = 6; foo(x); foo(x+1); return 0; }下面是OpenFOAM中一个非常简单的CFD求解器代码:
scalar packedAlpha ( readScalar ( kinematicCloud.particleProperties().subDict("constantProperties") .lookup("packedAlpha") ) ); scalar packedAlphac(1.0 - packedAlpha); // Update alphac from the particle locations alphac = max(1.0 - kinematicCloud.theta(), packedAlphac); alphac.correctBoundaryConditions(); surfaceScalarField alphacf("alphacf", fvc::interpolate(alphac)); surfaceScalarField alphaPhic("alphaPhic", alphacf*phic); autoPtr<incompressible::turbulenceModel> continuousPhaseTurbulence ( incompressible::turbulenceModel::New(Uc, phic, continuousPhaseTransport) );很明显,OpenFOAM虽然是使用C++编写的,但是OpenFOAM的代码对于不会OpenFOAM的C++(即使熟练工),也完全不明白OpenFOAM的C++代码是什么。
主要原因是OpenFOAM完全的面向对象。你看到的OpenFOAM的代码每一个都是对象,比如
surfaceScalarField是一个对象,incompressible::turbulenceModel是一个对象,kinematicCloud是一个对象。用一个最简单的例子表示面向对象和面向过程的区别:如果我们要求解矩阵
A,面向过程是这样的代码:solve(A);//矩阵A是一个参数面向对象是这样的代码:
A.solve();//矩阵A是一个对象再用一个小李子强调一下区别,如果你在求解矩阵
A的时候,同时需要aaaa,bbbb,cccc,dddd,eeee等5个参数,面向过程是这个样子:solve(A,aaaa,bbbb,cccc,dddd,eeee);//矩阵A是一个参数面向对象是这样的代码:
A.solve();//矩阵A是一个对象另一个面向过程和面向对象的例子:
dog(eat, shit);//面向过程,2个参数 dog.eat(shit);//面向对象,1个参数你的参数越多,你的传入参数越多。有可能你50行代码全是参数!!上面只是一个最容易理解的面向对象的举例,当然不仅仅是参数的区别。
继承,封装,多态
如果面向对象、面向过程把你搞晕了,这个主题可能会更晕。继承,封装,多态三个老哥可以最大化的减少代码复用。
继承
我们在面向对象的基础上,再举个小李子。如果我们需求定义OpenFOAM中
fvScalarMatrix和fvVectorMatrix对象的求解(实际上OpenFOAM已经帮你写好了,因此你不需要去关注到底怎么写,这也是后面要提及的封装),或许可以这样做://- fvScalarMatrix的函数定义 fvScalarMatrix::solve() { int a = 1; int b = 1; int c = 1; int d = 1; int e = a + b + c + d; //... } //- fvVectorMatrix的函数定义 fvVectorMatrix::solve() { int a = 1; int b = 1; int c = 1; int d = 1; int e = a + b + c + d; //... }我们暂且不去管
e = a + b + c + d有什么用(其实我就是瞎写的),但是很明显,对于不同的fvScalarMatrix和fvVectorMatrix,每个函数体内都需要写这些函数。对于OpenFOAM这种大型CFD求解代码,代码复用是难以接受的。面向对象中的继承可以一定程度上解决这个问题。我们这样考虑:既然
fvScalarMatrix和fvVectorMatrix都需要计算e = a + b + c + d,为什么不定义一个总管来计算,然后在fvScalarMatrix和fvVectorMatrix调用就可以了?这种思想形成了面向对象中的继承。因此上面的代码可以这样写:
//- 大总管 fvMatrix::calculateE() { int a = 1; int b = 1; int c = 1; int d = 1; int e = a + b + c + d; } //- fvScalarMatrix是fvMatrix类型的继承类 fvScalarMatrix::solve() { calculateE() //... } //- fvVectorMatrix是fvMatrix类型的继承类 fvVectorMatrix::solve() { calculateE() //... }在OpenFOAM代码中,这种通过继承减少代码复用的情况在每一个类中都可以见到,比如在
viscosity粘度模型中,具体的幂率粘度模型以及BC粘度模型都可以调用viscosity(大总管)中定义的strainRate()函数: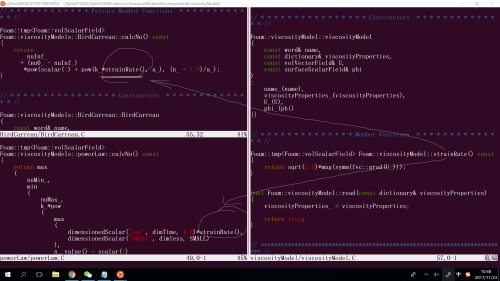
多态
面向对象中的多态主要可以实现函数的多重定义,也可以减少代码复用并且使得代码架构更加简洁。在说起多态的时候,我更倾向于从OpenFOAM中的运行时选择 RunTimeSelection谈起。
运行时选择在CFD中非常重要,举个小李子,如果你在算法中需要使用RANS湍流模型,你在传统的代码上需要这样定义
RASN.solve();如果你不知道选择RANS还是LES还是DNS等,你可能要通过关键词来实现如:
if (turbulenceType == "RANS") RANS.solve(); if (turbulenceType == "LES") LES.solve(); if (turbulenceType == "PANS") PANS.solve(); if (turbulenceType == "DES") DES.solve(); else DNS.solve();你大可以通过这种
if来实现选择具体的湍流模型,但是这种每个时间步进行的选择是耗费时间的!运行时选择是结合智能指针的一种机制。如果你不了解指针或者你觉得指针头晕,我用下面这个代码表示通过运行时选择对上述代码进行的简化:
autoPtr<turbulenceModel> turPtr(turPtr::New(turbulenceType)); turPtr->solve();是的,下面两行实现了上面N行的效果。最重要的是,你省略了大量的判断语句。
下面是OpenFOAM中真实的通过多态实现的自动选择功能。在计算升力
LiftForce的时候,需要调用升力系数Cl,OpenFOAM把具体的StaffMay升力系数计算方法和Tomiyama省力系数计算方法作为继承类,实现了Cl()函数的多态。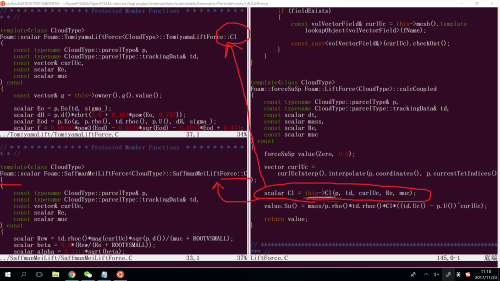
封装
面向对象最后一个特性就是封装了。封装主要是可以把你的实现(函数)隐藏起来,并且不让用户知道。由于OpenFOAM是开源的代码,因此OpenFOAM并没有此意。
这种隐藏实现的细节的另一个特点是用户不需要关心到底是怎么样去实现,比如OpenFOAM里面的
fvScalarMatrix类型,在求解的时候,用户只需要TEqn.solve()就可以。完全不需要关心里面具体怎样solve()的。Your Code Your Way
所以说,由于OpenFOAM这种逆天神级的C++操作,用户在学习OpenFOAM代码的时候,基本上找不到C++基本的各种类型,完全是OpenFOAM自己定义的类型。因此这个学习OpenFOAM的过程,更倾向是在学习OpenFOAM的自定义类型而不是学习C++,当然这个要建立在学习C++基础之上。
如果各种类继承感觉很晕的话,用户一定就要用么?No。连Elsevier在投稿的时候都提供
Your Paper Your Way,你自己写的代码当然也是Your Code Your Way。完全可以面向过程,不用管传递引用还是指针,直接传递拷贝复制就可以。大家更关心的是你的代码能不能出结果,写文章,慢一点还是相对可以忍受。底层和架构
很遗憾上面谈的也只是OpenFOAM代码中的冰山一角,并且和CFD的具体算法模型关系很大。OpenFOAM更加底层的实现偏离CFD很远,比如数据输入和输出、MPI的实现、网格分解算法等,这些我也没有研究过。其他的ID可能会有更丰富的讨论。
谈完了美妙绝伦的继承、封装和多态,剩下的就是架构。不管是在CFD代码中,还是互联网大厂中,架构师一般都是最高薪的。当然互联网那面的架构师由于行业特性,基本上属于管理层了。还有好多不同的架构师定义。
但是CFD代码架构师和互联网那面还有所区别,在这里我们讨论纯粹的CFD代码架构师而不是那种设计到管理层面的架构师。一个好的CFD架构师需要能在统揽算法全局的基础上,在顶端设计好代码结构。举个例子,比如OpenFOAM中的
thermo类型,这是一个巨大的类。架构师的作用就是要搭建好这个类型的基本类型以及衍生类型,哪些需要提供接口,哪些可以封闭,哪些可以嵌套。否则的话你可能加一个算法,要么硬植入,要么重新架构。这也就是为什么我最近重新写代码了,因为要重新设计代码的结构。很遗憾目前我还不能做到对算法有一个全局的概念,远不能达到架构师的地步。
最后,可能有的刚入门CFD的朋友不知道我说的是什么,但你总会明白的。
在这里声明下:这篇文章是李东岳写的。

- 闭源CFD求解器,例如
-
此坑甚深,marryed first then to be a CFDer
-
-
@东岳 谢谢东岳老师的分享。
我想补充一点:
开源软件虽然是大多数人都听过的,但实际上更准确的说法是自由软件(FOSS )。这是 OF 官网的自我介绍:
OpenFOAM is the leading free, open source software for computational fluid dynamics (CFD), owned by the OpenFOAM Foundation and distributed exclusively under the General Public Licence (GPL).
两个术语:"开源"和"自由"的区别:wiki 上有这样的解释。
Yours in CFD,
Ran
-
@random_ran 刚开始是英语用词的争议,用的是free。本来想表达自由,但是free很容易被理解成免费,所以free这个词受到了抵制(程序员也要吃饭)。才有了open source这个词。FOSS组织成立早,那时候还没free和open source争议。但是你看 开源中国,没有叫自由中国。新的开源软件多以 libre- 前缀冠名,都是为了避免用free。free中的免费含义有对程序员工作成果的不尊重。
事实上没有任何代码是自由的,开源的代码都有许可证,代码的使用都要受许可证限制。
至于更细致的划分,一群满口哲学的程序员,天天争、分辨、一大堆许可证。
 你都混论坛好久了 哈哈
你都混论坛好久了 哈哈