并行效率疑问
-
简单说一下case的情况:
三维圆柱绕流,pisoFoam, incompressible solver, LES dynamic k equation, Re 10^5, 3千万结构网格。
为了加速运算,又使用了576核试算,infinband, 24cores/node, 32 Gb mem /node。预计比288核那个case要快,结果挺意外的:
288 core 运行到0.014 second 的时候 clockTime 631 s
Time = 0.014 Courant Number mean: 0.0209991 max: 0.860686 DILUPBiCG: Solving for Ux, Initial residual = 0.000686338, Final residual = 5.79235e-09, No Iterations 3 DILUPBiCG: Solving for Uy, Initial residual = 0.000616596, Final residual = 2.39462e-07, No Iterations 2 DILUPBiCG: Solving for Uz, Initial residual = 0.25073, Final residual = 2.22608e-08, No Iterations 3 GAMG: Solving for p, Initial residual = 0.0951268, Final residual = 0.00450444, No Iterations 2 time step continuity errors : sum local = 3.43222e-08, global = 3.79731e-10, cumulative = -1.1601e-09 GAMG: Solving for p, Initial residual = 0.00459438, Final residual = 0.000221683, No Iterations 11 time step continuity errors : sum local = 1.67411e-09, global = -1.41906e-10, cumulative = -1.302e-09 GAMG: Solving for p, Initial residual = 0.000220326, Final residual = 9.99438e-08, No Iterations 59 time step continuity errors : sum local = 7.78239e-13, global = -1.40881e-16, cumulative = -1.302e-09 DILUPBiCG: Solving for k, Initial residual = 0.0347117, Final residual = 7.93887e-08, No Iterations 2 bounding k, min: -1.42701e-10 max: 6.66159e-05 average: 7.69531e-09 ExecutionTime = 627.61 s ClockTime = 631 s576 核 ClockTime = 2914 s
Time = 0.014 Courant Number mean: 0.0209908 max: 0.853335 DILUPBiCG: Solving for Ux, Initial residual = 0.000742593, Final residual = 7.78633e-07, No Iterations 2 DILUPBiCG: Solving for Uy, Initial residual = 0.000648146, Final residual = 2.82185e-07, No Iterations 2 DILUPBiCG: Solving for Uz, Initial residual = 0.244847, Final residual = 6.20964e-07, No Iterations 2 GAMG: Solving for p, Initial residual = 0.0907169, Final residual = 0.00453577, No Iterations 31 time step continuity errors : sum local = 3.71049e-08, global = 5.32494e-10, cumulative = -4.51107e-09 GAMG: Solving for p, Initial residual = 0.00511943, Final residual = 0.000253917, No Iterations 334 time step continuity errors : sum local = 1.90337e-09, global = 1.51918e-11, cumulative = -4.49588e-09 GAMG: Solving for p, Initial residual = 0.000284638, Final residual = 9.81376e-08, No Iterations 385 time step continuity errors : sum local = 6.5267e-13, global = 7.25236e-15, cumulative = -4.49587e-09 DILUPBiCG: Solving for k, Initial residual = 0.0346825, Final residual = 2.17503e-08, No Iterations 2 bounding k, min: -9.64626e-16 max: 6.49695e-05 average: 7.68376e-09 ExecutionTime = 2903.75 s ClockTime = 2914 s除了decompose的方式不一样之外:
hierarchicalCoeffs // 576 core { n (4 4 36); delta 0.00001; order xyz; }hierarchicalCoeffs // 288 core { n (16 9 2); delta 0.001; order xyz; }其他的设置完全一样。
想问问论坛里有这方面经验的人朋友,愿意分享一下你的经验吗?是从求解器的选择入手?从数值scheme方面,还是decompose的方式? 虽然烧的是国家的机器,但是还是能节省点。LOL。
-
@random_ran
是 GAMG 在拖你的后腿,这么多核的情况下,你可以试试用 PCG + DIC 来求解 p 方程,这个方法并行效率会高一些。 -
谢谢你的建议,确实PCG+DIC 解p方程的效率有所提高,目前新的case还在run。
Time = 0.048 //576 cores Courant Number mean: 0.0211288 max: 0.859123 DILUPBiCG: Solving for Ux, Initial residual = 0.000456629, Final residual = 3.65897e-07, No Iterations 2 DILUPBiCG: Solving for Uy, Initial residual = 0.000477652, Final residual = 4.92182e-07, No Iterations 2 DILUPBiCG: Solving for Uz, Initial residual = 0.235746, Final residual = 6.0203e-08, No Iterations 3 DICPCG: Solving for p, Initial residual = 0.21036, Final residual = 0.0103945, No Iterations 676 time step continuity errors : sum local = 3.27749e-08, global = 2.74055e-11, cumulative = 2.44545e-08 DICPCG: Solving for p, Initial residual = 0.0069283, Final residual = 0.000342288, No Iterations 700 time step continuity errors : sum local = 1.71314e-09, global = -5.01474e-11, cumulative = 2.44043e-08 DICPCG: Solving for p, Initial residual = 0.000423809, Final residual = 2.08942e-05, No Iterations 723 time step continuity errors : sum local = 1.06217e-10, global = 5.3039e-13, cumulative = 2.44049e-08 DILUPBiCG: Solving for k, Initial residual = 0.0159443, Final residual = 3.974e-07, No Iterations 3 bounding k, min: -6.91417e-13 max: 0.0010178 average: 3.66373e-08 ExecutionTime = 1327.45 s ClockTime = 1333 sTime = 0.048 //288 core Courant Number mean: 0.0211368 max: 0.860415 DILUPBiCG: Solving for Ux, Initial residual = 0.000472671, Final residual = 1.86206e-07, No Iterations 2 DILUPBiCG: Solving for Uy, Initial residual = 0.000470667, Final residual = 1.50369e-07, No Iterations 2 DILUPBiCG: Solving for Uz, Initial residual = 0.227442, Final residual = 1.43158e-08, No Iterations 3 GAMG: Solving for p, Initial residual = 0.14952, Final residual = 0.00727048, No Iterations 3 time step continuity errors : sum local = 3.21523e-08, global = 1.32072e-09, cumulative = -2.68714e-11 GAMG: Solving for p, Initial residual = 0.0105374, Final residual = 0.000436311, No Iterations 17 time step continuity errors : sum local = 1.38004e-09, global = 2.02486e-11, cumulative = -6.62288e-12 GAMG: Solving for p, Initial residual = 0.000588406, Final residual = 9.97916e-08, No Iterations 102 time step continuity errors : sum local = 2.47533e-13, global = 3.66548e-17, cumulative = -6.62284e-12 DILUPBiCG: Solving for k, Initial residual = 0.0159342, Final residual = 3.67721e-08, No Iterations 3 bounding k, min: -1.80015e-12 max: 0.00101339 average: 3.66396e-08 ExecutionTime = 1824.48 s ClockTime = 1831 s scalarTransport write: DILUPBiCG: Solving for s, Initial residual = 0.00981188, Final residual = 7.3898e-09, No Iterations 2我把decompose的方式用得和288 cores 那个case 类似
hierarchicalCoeffs //576 case { n (32 9 2); delta 0.001; order xyz; }hierarchicalCoeffs //288 case { n (16 9 2); delta 0.001; order xyz; } -
@cfd-china
你说得很对。从hierarchical到scotch是我要考虑的一个方向。不过由于decompose的时间花费,现在我在处理一些solver上的选择,这样可以不decompse。这个表格是我现在做过的一些case。
我的目标计算时间是1个小时算出0.5second。
#case p-solver #核心数 decompose 方法 数值精度 求解器 1小时后,模拟时间 湍流模型 #PISO 矫正次数 1 GAMG+symGaussSeidel 576 hiera (32 9 2) -6 pisoFoam - LES-kqE 3 2 - - - - - - - - 3 PCG+DIC 576 hiera (32 9 2) -6 pisoFoam 0.133 LES-WALE 3 4 PCG+DIC 576 hiera (32 9 2) -6 pisoFoam 0.129 LES-kqE 3 5 PCG+DIC 576 hiera (32 9 2) -6 pisoFoam 0.125 LES-TKE 3 6 PCG+DIC 576 hiera (32 9 2) -7 pisoFoam 0.125 LES-TKE 3 7 8 9 GAMG+smootherGaussSeidel 576 hiera (4 4 36) -7 pisoFoam 0.015(2914s) LES-TKE 3 10 GAMG+smootherGaussSeidel 288 hiera (16 9 2) -6 pisoFoam 0.171 LES-TKE 2 11 GAMG+smootherGaussSeidel 288 hiera (16 9 2) -6 pisoFoam 0.132 LES-TKE 3 -
$ checkMesh
Create time Create polyMesh for time = 0 Time = 0 Mesh stats points: 34617600 faces: 102296400 internal faces: 100743600 cells: 33840000 faces per cell: 6 boundary patches: 5 point zones: 0 face zones: 0 cell zones: 0 Overall number of cells of each type: hexahedra: 33840000 prisms: 0 wedges: 0 pyramids: 0 tet wedges: 0 tetrahedra: 0 polyhedra: 0 Checking topology... Boundary definition OK. Cell to face addressing OK. Point usage OK. Upper triangular ordering OK. Face vertices OK. Number of regions: 1 (OK). Checking patch topology for multiply connected surfaces... Patch Faces Points Surface topology INLET 28200 28848 ok (non-closed singly connected) OUTLET 28200 28848 ok (non-closed singly connected) CYLINDER 56400 57600 ok (non-closed singly connected) FRONT_CYC 720000 721200 ok (non-closed singly connected) BACK_CYC 720000 721200 ok (non-closed singly connected) Checking geometry... Overall domain bounding box (-20 -20 0) (20 20 3.07458) Mesh has 3 geometric (non-empty/wedge) directions (1 1 1) Mesh has 3 solution (non-empty) directions (1 1 1) Boundary openness (9.81794e-16 9.03981e-18 9.17862e-15) OK. Max cell openness = 3.5214e-16 OK. Max aspect ratio = 229.976 OK. Minimum face area = 7.49334e-07. Maximum face area = 0.022353. Face area magnitudes OK. Min volume = 4.90189e-08. Max volume = 0.00146226. Total volume = 3861.2. Cell volumes OK. Mesh non-orthogonality Max: 4.97612e-05 average: 0 Non-orthogonality check OK. Face pyramids OK. Max skewness = 0.006519 OK. Coupled point location match (average 4.44139e-16) OK. Mesh OK. End -
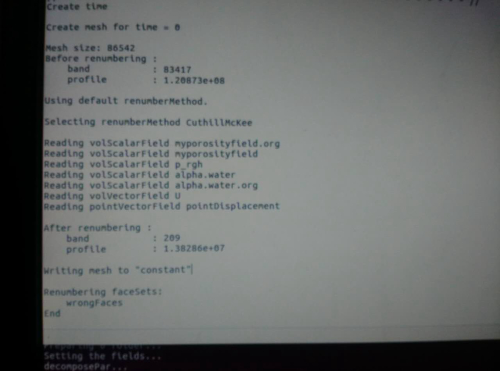
@random_ran 不知道你运行之前是否 renumberMesh?用了这个之后能减少求解方程时的迭代次数。
另外,还可以尝试 PCG + GAMG,用 GAMG当 PCG 的 smoother。
-
-
@random_ran 你好,我想问一下,我运用scotch方法剖分了网格,并行运算时提示网格出现下述问题是咋回事:
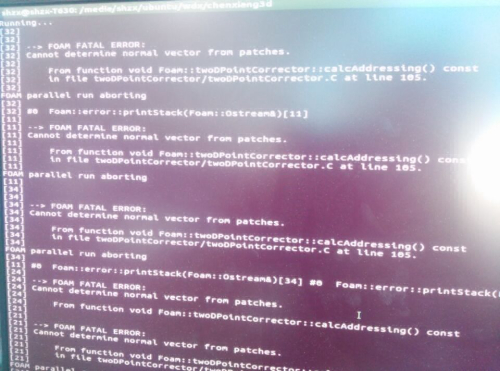
大概提示是找不到法向量,我对应到程序中是这个地方:
103 if (mag(pn) < VSMALL) 104 { 105 FatalErrorInFunction 106 << "Cannot determine normal vector from patches." 107 << abort(FatalError); 108 } 109 else 110 { 111 pn /= mag(pn); 112 } 113大概意思就是分块的面积太小了,找不到法向量?
用simple方法提示的错误不一样,大意几个地方网格的交界面有问题。
可是不管哪个方法,我都检查了网格,checkMesh没问题,单核也可以计算。
我怀疑是不是加密的关系,一般感觉加密的level到3就容易出问题,我这个就到了3,请问你遇到过类似的情况吗?
-
@random_ran 多谢建议,不过确实都没有任何问题。。。
等过一段我贴上来:)
-
好贴子,马住。另外推荐一个连接:
http://nscc-gz.cn/newsdetail.html?6151 -
你是在哪个超算中心跑的算例?用的是什么规格的机器
-
我是在 Université de Sherbrooke 的长毛象2号超算上算的。这篇帖子的一楼最后我详细描述了硬件。
我没有在专门搞CFD的组里搞CFD,机时的分配只有100-CPU年。
-
@random_ran 在超算上安装哪个版本的openfoam?是自己安装的么?我现在跑算例要在超算上计算,现在还处在调研阶段,对超算的情况不是很了解。希望你能多给我一些建议
-
@random_ran renumberMesh这个命令你用过么?(我看贴上有人用过)用过的话你跑的是什么算例模型,计算效率提高了多少,计算结果准确么?我的算例也是圆柱绕流湍流模型验证 是否可用这个命令?
-
@random_ran
顶长毛象

@bingningmeng45
renumberMesh看你需求吧,锦上添花的东西,不用也可以,用了更好,莫非你并行遇到了瓶颈。 -
@random_ran renumberMesh 这个如何操作运行?直接在终端输入吗
-
建议你这样做:
cd $FOAM_TUTORIALS grep -rnw './' -e "renumberMesh"然后
emacs ./incompressible/pisoFoam/les/motorBike/motorBike/Allrun就会发现你想要的东西了。
我的OpenFOAM版本是v4.1。
操作系统是CentOS Linux release 7.3.1611 (Core)。祝好。
-
最近看了看这个
renumberMesh,觉得可能有一些更深入的算法在里面,看完之后,个人觉得不必深究了,就类似OpenFOAM中的mpi库一样,除非你专门做mpi的。大体思路就是楼上们说的减少带宽。比如在求解100阶矩阵的时候,现存带宽可能为30,在进行迭代预处理的时候,可能会产生填入操作,但是依然位于带宽之内。renumberMesh或者在计算图形学中的reordering可以通过将矩阵和Adjacency matrix(不知道中文是什么)联系起来,重新排序,减少带宽,降低存储。在大型计算中,可以降低内存存储,大体就是这个意思。renumberMesh中植入的是Cuthill–McKee algorithm,详细了解可google。个人觉得有点偏离CFD,了解了解就好。 -
- ilu0没有填入,of玩的ldu全是用的不填入的算法,不然ldu数据结构包不住,得像aeroFoam那样玩更高级的数据结构,
- ldu矩阵renumber不降低单次迭代的flops数量!那么省出来的时间必须有个说法,要么谱半径更小,收敛所需迭代数减少,要么平均每个flops用时减少(cache命中率提高)。总时间=迭代数每次迭代的flops数每个flops平均用时,对吧。
- renumber有效性说明现代cfd程序更多地受限于储存速度,cache命中率啥的,这个东西是有瓶颈的,未来cfd程序的套路可能就得变了。
- 你说的半带宽那套是针对banded structure的老的数据结构了,算法和数据结构是配套的,单看算法不看数据结构没有任何意义。
-
ilu0没有填入,of玩的ldu全是用的不填入的算法
你说的半带宽那套是针对banded structure的老的数据结构了在另一个帖子我也看到你说的LDU,这只是OpenFOAM存储矩阵的方式,没有任何算法的存在意义,OpenFOAM编程可以酸则LDU,也可以选择Coordinate list (COO),也可以选择List of lists (LIL)。ILU0是ILU0算法,LDU是OpenFOAM的存储矩阵的方式。我觉得你弄混了。
另外,矩阵存在带宽是客观存在的,不管你怎么存储。是LDU还是LIL。
矩阵存储和带宽是两个概念:https://en.wikipedia.org/wiki/Sparse_matrix#Compressed_sparse_row_.28CSR.2C_CRS_or_Yale_format.29
对ILU矩阵进行reordering是另一个概念:
Saad, Yousef. Iterative methods for sparse linear systems. Society for Industrial and Applied Mathematics, 2003. -
对ILU矩阵进行reordering是另一个概念:
你弄混了,从来没有ILU矩阵,是ldu矩阵吧。
COO/LIL都是sparse matrix的储存格式之一,但是不同储存格式做matrix product或者其他矩阵操作时效率是不一样的,比如CSR和CSC一个做M*x效率高,另一个做transpose(M)*x效率更高。这就是我说的具体数据结构和算法是相关的,一个操作在COO和LDU上的时间复杂度是不一样的。但是很容看出来,ldu矩阵下,很多操作的浮点操作数flops(差不多就是时间复杂度)不随reordering变化。
同时OF默认实现的只有LDU矩阵,没有coo/lil格式的,除了一些GPU扩展。所以OF没法直接调用petsc,也没有依赖别的线性代数软件包,blas,lapack之类的一个没用上,代码也很臃肿。
ILU0是fill in=0的ILU算法,可以基于任何矩阵实现,但是对于sparse matrix来说,fill in为0意味着前后indexing的部分可以不用动,只要把data部分改了就行,甚至指向另一个data_ilu就可以了。OF LDU matrix相当于所有OF里的矩阵的indexing部分都是一样,你能改变的只有data_ptr,所以OF只能玩ilu0,玩ilu1都不行。虽然OF的ldu是很紧凑高效的矩阵内存结构,但是还是有局限性的。
我关注的问题是为什么矩阵减小带宽会带来加速?用半带宽解释我觉得潜在假设就是:同样的矩阵内容,半带宽小==矩阵操作快。但是操作数不变的情况下操作加快了,就是cache的问题了。
-
我关注的问题是为什么矩阵减小带宽会带来加速?
如果去看
renumberMesh或者ANSYS关于reorder的描述,并没有说加快计算,只是说减少带宽和提高内存使用率。Renumbers the cell list in order to reduce the bandwidth, reading and renumbering all fields from all the time directories.Reordering the domain can improve the computational performance of the solver by rearranging the nodes, faces, and cells in memory. The Mesh/Reorder submenu contains commands for reordering the domain and zones, and also for printing the bandwidth of the present mesh partitions. The domain can be reordered to increase memory access efficiency, and the zones can be reordered for user-interface convenience. The bandwidth provides insight into the distribution of the cells in the zones and in memory. -
这个说得比较清楚。内存效率提升,但是也没说计算浮点操作数减少。
%pylabUsing matplotlib backend: Qt5Agg Populating the interactive namespace from numpy and matplotlibA矩阵是对角占优的矩阵
A=array([5 ,-2 ,0 ,0 ,0, -2 ,5,-2,0,0, 0 , -2, 5,-2,0, 0,0,-2,5,-2, 0,0,0,-2,5]) A = A.reshape([5,5]) Aarray([[ 5, -2, 0, 0, 0], [-2, 5, -2, 0, 0], [ 0, -2, 5, -2, 0], [ 0, 0, -2, 5, -2], [ 0, 0, 0, -2, 5]])P矩阵是排列矩阵,交换第一个元素和第5个元素
P=array([0 ,0 ,0 ,0 ,1, 0,1,0,0,0, 0 , 0, 1,0,0, 0,0,0,1,0, 1,0,0,0,0]) P = P.reshape([5,5]) Parray([[0, 0, 0, 0, 1], [0, 1, 0, 0, 0], [0, 0, 1, 0, 0], [0, 0, 0, 1, 0], [1, 0, 0, 0, 0]])排列矩阵的转置是自身的逆
P.T.dot(P)array([[1, 0, 0, 0, 0], [0, 1, 0, 0, 0], [0, 0, 1, 0, 0], [0, 0, 0, 1, 0], [0, 0, 0, 0, 1]])作用到矩阵A上,生成矩阵B
B=P.T.dot(A).dot(P) Barray([[ 5, 0, 0, -2, 0], [ 0, 5, -2, 0, -2], [ 0, -2, 5, -2, 0], [-2, 0, -2, 5, 0], [ 0, -2, 0, 0, 5]])上下三角矩阵和对角矩阵
#GS iteration L=tril(B,-1) Larray([[ 0, 0, 0, 0, 0], [ 0, 0, 0, 0, 0], [ 0, -2, 0, 0, 0], [-2, 0, -2, 0, 0], [ 0, -2, 0, 0, 0]])D=diag(diag(B)) Darray([[5, 0, 0, 0, 0], [0, 5, 0, 0, 0], [0, 0, 5, 0, 0], [0, 0, 0, 5, 0], [0, 0, 0, 0, 5]])U=triu(B,1) Uarray([[ 0, 0, 0, -2, 0], [ 0, 0, -2, 0, -2], [ 0, 0, 0, -2, 0], [ 0, 0, 0, 0, 0], [ 0, 0, 0, 0, 0]])M_GS is Gauss-Seidel iter. matrix
M_GS=inv(L+D).dot(U) M_GSarray([[ 0. , 0. , 0. , -0.4 , 0. ], [ 0. , 0. , -0.4 , 0. , -0.4 ], [ 0. , 0. , -0.16 , -0.4 , -0.16 ], [ 0. , 0. , -0.064, -0.32 , -0.064], [ 0. , 0. , -0.16 , 0. , -0.16 ]])spectral radius of GS iter.
spectral_radius_GS=max(abs(linalg.eig(M_GS)[0])) spectral_radius_GS0.48000000000000026M_J is Jacobi iter. matrix
M_J=inv(D).dot(U+L) M_Jarray([[ 0. , 0. , 0. , -0.4, 0. ], [ 0. , 0. , -0.4, 0. , -0.4], [ 0. , -0.4, 0. , -0.4, 0. ], [-0.4, 0. , -0.4, 0. , 0. ], [ 0. , -0.4, 0. , 0. , 0. ]])spectral radius of iter. matrix
spectral_radius_J=max(abs(linalg.eig(M_J)[0])) spectral_radius_J0.69282032302755092Compare A with B
L,D,U=tril(A,-1),diag(diag(A)),triu(A,1) M_GS=inv(L+D).dot(U) spectral_radius_GS=max(abs(linalg.eig(M_GS)[0])) spectral_radius_GS0.47999999999999987对比可以看出来,reorder之后迭代矩阵谱半径几乎没变化。说明加速主要来源于内存访问效率的提高。
某种意义上来说,说明CPU没吃饱,上菜速度太慢了。以后pde模拟程序的优化方向大概应该是加快上菜速度。。。
-
@CFDngu 您好!我也遇到了因renumberMesh而不能计算的问题,推测问题和网格有关。没有边界层时,使用renumberMesh没问题且速度会明显变快;在加密边界层至0.00001m后,使用renumberMesh就会出错,当然不使用renumberMesh,也只能单核计算,并行还是会出错。不知道您最近有没有进展,我的问题和算例文件详细描述在 http://www.cfd-china.com/topic/2548/openfoam中cyclicami周期边界在有边界层时出现问题 。
如果可以,我还想咨询下,renumberMesh是否有设置精度的选项?或者openfoam重某个文件可以设置精度?个人推测网格尺寸变小,会在关联cyclic或cyclicAMI的周期边界时,出现截断误差导致误判?
-
PCG在几百核并行的时候速度更快,但是根本收敛不了吗?GAMG在这么多核的时候效率又很慢,貌似没有最优解?
-
@random_ran 我目前想联系国家这边的超算,请问你有了解国内的超算速度吗?哪里的会比较推荐?谢谢
-
目前了解到PCG在多核并行计算的时候效率会比GAMG更高,那这个多核有大概的一个参考数值吗?之前看到过是五百核。
另外这二者对于计算的准确度上面有没有优劣性,PCG在网格数太多的情况下真的会收敛不了?
最后,多核的时候用scotch会更好吗?之前在论坛上看过对于流向明确的算例,比如圆管,用simple,在流动方向上多分块,效果也还可以。
我目前在400核并行计算7500W的网格,圆管加热流动,用scotch和simple算起来速度差不多。GAMG+DIC跟PCG+DIC的速度也差不多。不知有何高见,谢谢!
-
@Calf-Z-DNS 我一直对稀疏线性系统感兴趣但是好像有生之年不可能用几年时间去研究他们了。哎。PBiCGStab和PBiCG的算法就在那,但是也没透彻分析过。只不过从个人实践来看我只用PBiCGStab没用过PBiCG。精度没对比过。个人觉得线性系统的精度不足以抹杀掉CFD模型和迭代的精度。你若有结果,欢迎反馈
你后来那个做怎么样了?DNS浮力驱动刘的
-
长风破浪会有时,直挂云帆济沧海
-
CFD服务器 http://dyfluid.com/DMmodel.html
机架式服务器 http://dyfluid.com/DMCmodel.html
GPU服务器 http://dyfluid.com/gpu.html -
OpenFOAM 矩阵计算效率是可以更高,这点没有疑问. 矩阵计算效率高不高 主要取决于 MPI 通信
1000 processors 以上 不同节点上 计算 OpenFOAM 要重构效率高不高除了算法,计算问题类型, 代码优化等有关系
大牛说 下一代cfd 需要 大规模计算机网格 + Algorithm + Coding 整体考虑 我觉得很有道理
问过openfoam developer, 他的意思是 OpenFOAM is a general CFD solver. They want to solve specific problem to make money (ESI).
-
@random_ran 在 并行效率疑问 中说:
以后多核计算前,我都会renumberMesh 的
您好!请问,在进行多核计算时,我应该先decompose,再renumber,还是应该 先renumber再decompose呢?谢谢!